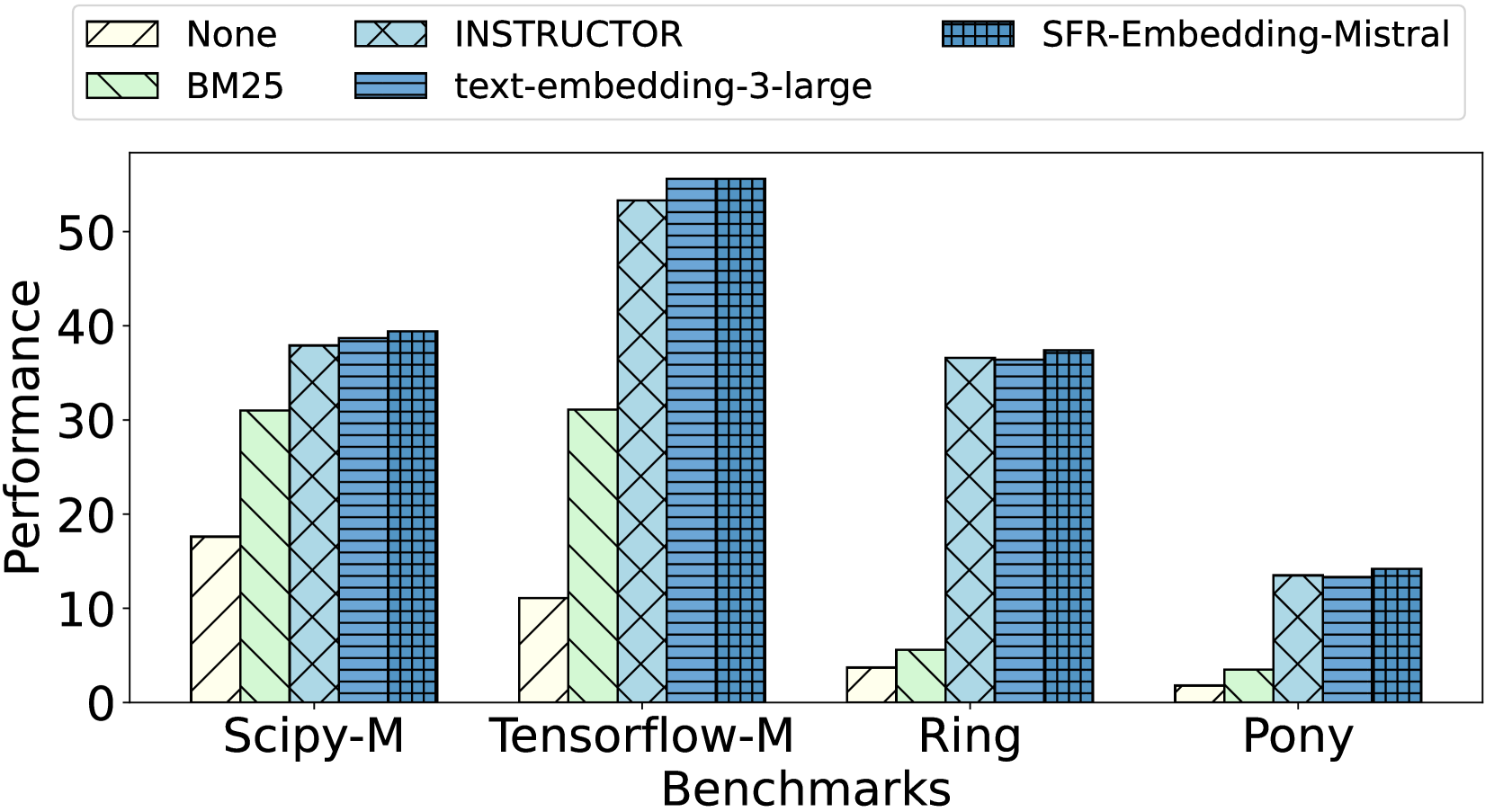
## Bar Chart: Model Performance Across Benchmarks
### Overview
The chart compares the performance of five different models (None, BM25, INSTRUCTOR, text-embedding-3-large, SFR-Embedding-Mistral) across four benchmarks (Scipy-M, Tensorflow-M, Ring, Pony). Performance is measured on a scale from 0 to 50, with SFR-Embedding-Mistral consistently achieving the highest scores.
### Components/Axes
- **X-axis (Benchmarks)**: Scipy-M, Tensorflow-M, Ring, Pony (categorical)
- **Y-axis (Performance)**: Numerical scale from 0 to 50
- **Legend**:
- None (light yellow, diagonal stripes)
- BM25 (light green, diagonal stripes)
- INSTRUCTOR (light blue, diagonal stripes)
- text-embedding-3-large (light blue, crosshatch)
- SFR-Embedding-Mistral (dark blue, grid)
### Detailed Analysis
1. **Scipy-M**:
- None: ~18
- BM25: ~31
- INSTRUCTOR: ~38
- text-embedding-3-large: ~39
- SFR-Embedding-Mistral: ~40
2. **Tensorflow-M**:
- None: ~11
- BM25: ~32
- INSTRUCTOR: ~53
- text-embedding-3-large: ~55
- SFR-Embedding-Mistral: ~55
3. **Ring**:
- None: ~4
- BM25: ~6
- INSTRUCTOR: ~37
- text-embedding-3-large: ~37
- SFR-Embedding-Mistral: ~38
4. **Pony**:
- None: ~2
- BM25: ~4
- INSTRUCTOR: ~14
- text-embedding-3-large: ~14
- SFR-Embedding-Mistral: ~15
### Key Observations
- **SFR-Embedding-Mistral** dominates all benchmarks, achieving the highest performance (40–55 range).
- **None** (baseline) performs poorly across all benchmarks (2–18 range).
- **Tensorflow-M** shows the largest performance gap (~44 between None and SFR-Embedding-Mistral).
- **Pony** has the lowest absolute performance (~2–15 range), suggesting it may be less optimized for these tasks.
### Interpretation
The data demonstrates that SFR-Embedding-Mistral significantly outperforms other models, likely due to its advanced architecture or training methodology. The consistent trend across benchmarks suggests it excels at generalizable tasks. The drastic drop in performance for "None" highlights the importance of model sophistication. Pony's low scores may indicate niche applicability or suboptimal design for these benchmarks. The correlation between model complexity (e.g., SFR-Embedding-Mistral's grid pattern vs. None's simplicity) and performance underscores the value of advanced embeddings in these tasks.