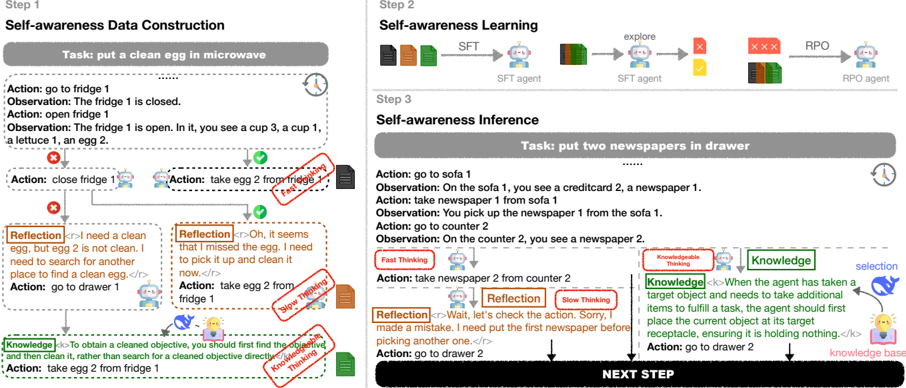
## Flowchart: Self-Awareness System Architecture
### Overview
The image depicts a three-step process for a self-aware robotic system:
1. **Self-awareness Data Construction** (Step 1)
2. **Self-awareness Learning** (Step 2)
3. **Self-awareness Inference** (Step 3)
Each step includes tasks, agent actions, observations, and reflective/knowledge-based annotations. The system uses colored feedback (red X, green check) and integrates SFT (Supervised Fine-Tuning) and RPO (Reinforcement Policy Optimization) agents.
---
### Components/Axes
#### Step 1: Self-awareness Data Construction
- **Task**: "put a clean egg in microwave"
- **Actions/Observations**:
- Action: "go to fridge 1"
- Observation: "The fridge 1 is closed."
- Action: "open fridge 1"
- Observation: "The fridge 1 is open. In it, you see a cup 3, a cup 1, a lettuce 1, an egg 2."
- Action: "close fridge 1"
- **Annotations**:
- **Reflection**: "I need a clean egg, but egg 2 is not clean. I need to search for another place to find a clean egg."
- **Knowledge**: "To obtain a cleaned objective, you should first find the objective and then clean it, rather than search for a cleaned objective directly."
#### Step 2: Self-awareness Learning
- **Components**:
- **SFT Agent**:
- Input: Documents (black, orange, green) labeled "explore"
- Output: Feedback (red X, green check)
- **RPO Agent**:
- Input: Feedback from SFT Agent
- Output: Processed documents (black, orange, green)
- **Flow**:
- SFT Agent → RPO Agent (via red X and green check signals)
#### Step 3: Self-awareness Inference
- **Task**: "put two newspapers in drawer"
- **Actions/Observations**:
- Action: "go to sofa 1"
- Observation: "On the sofa 1, you see a creditcard 2, a newspaper 1."
- Action: "take newspaper 1 from sofa 1"
- Observation: "You pick up the newspaper 1 from the sofa 1."
- Action: "go to counter 2"
- Observation: "On the counter 2, you see a newspaper 2."
- Action: "take newspaper 2 from counter 2"
- **Reflection**: "Wait, let’s check the action. Sorry, I made a mistake. I need to put the first newspaper before picking another one."
- **Knowledge**: "When the agent has taken a target object and needs to take additional items to fulfill a task, the agent should first place the current object at its target receptacle, ensuring it is holding nothing."
- **Annotations**:
- **Fast Thinking**: Red-highlighted decision node
- **Slow Thinking**: Green-highlighted reflective node
---
### Detailed Analysis
#### Step 1: Data Construction
- The agent attempts to retrieve a clean egg but discovers "egg 2" is dirty.
- **Reflection** triggers a correction: "go to drawer 1" to search for a clean egg.
- **Knowledge** emphasizes prioritizing object discovery before cleaning.
#### Step 2: Learning Process
- **SFT Agent** evaluates actions via exploration (explore → feedback).
- **RPO Agent** refines policies using SFT feedback (red X = error, green check = success).
- Color-coded documents (black, orange, green) represent data states.
#### Step 3: Inference and Correction
- The agent initially takes "newspaper 1" from the sofa but fails to place it in the drawer.
- **Reflection** identifies the error: "I need to put the first newspaper before picking another one."
- **Knowledge** enforces a rule: Place the current object before acquiring additional items.
---
### Key Observations
1. **Iterative Correction**: The system uses reflections to correct mistakes (e.g., dirty egg, misplaced newspaper).
2. **Feedback Integration**: Red X/green check signals guide RPO agent adjustments.
3. **Knowledge-Driven Actions**: Predefined rules (e.g., "place current object first") override fast thinking.
4. **Task Complexity**: Later steps (Step 3) involve multi-object handling and error recovery.
---
### Interpretation
The flowchart illustrates a hierarchical self-awareness framework:
- **Data Construction** builds task-specific observations.
- **Learning** refines agent behavior via feedback loops (SFT → RPO).
- **Inference** applies learned knowledge to execute tasks while correcting errors.
The system mimics human-like problem-solving:
- **Fast Thinking** (immediate actions) is tempered by **Slow Thinking** (reflection).
- **Knowledge** acts as a constraint to prevent redundant searches (e.g., seeking a clean egg directly).
Notably, the agent’s ability to self-correct (e.g., placing the first newspaper before the second) suggests a design inspired by cognitive architectures like SOAR or ACT-R. The use of colored feedback (red X/green check) aligns with reinforcement learning paradigms, while the knowledge base introduces symbolic reasoning.
---
**Language Note**: All text is in English. No non-English content detected.