## Line Graphs: Training Dynamics Across Different Strategies
### Overview
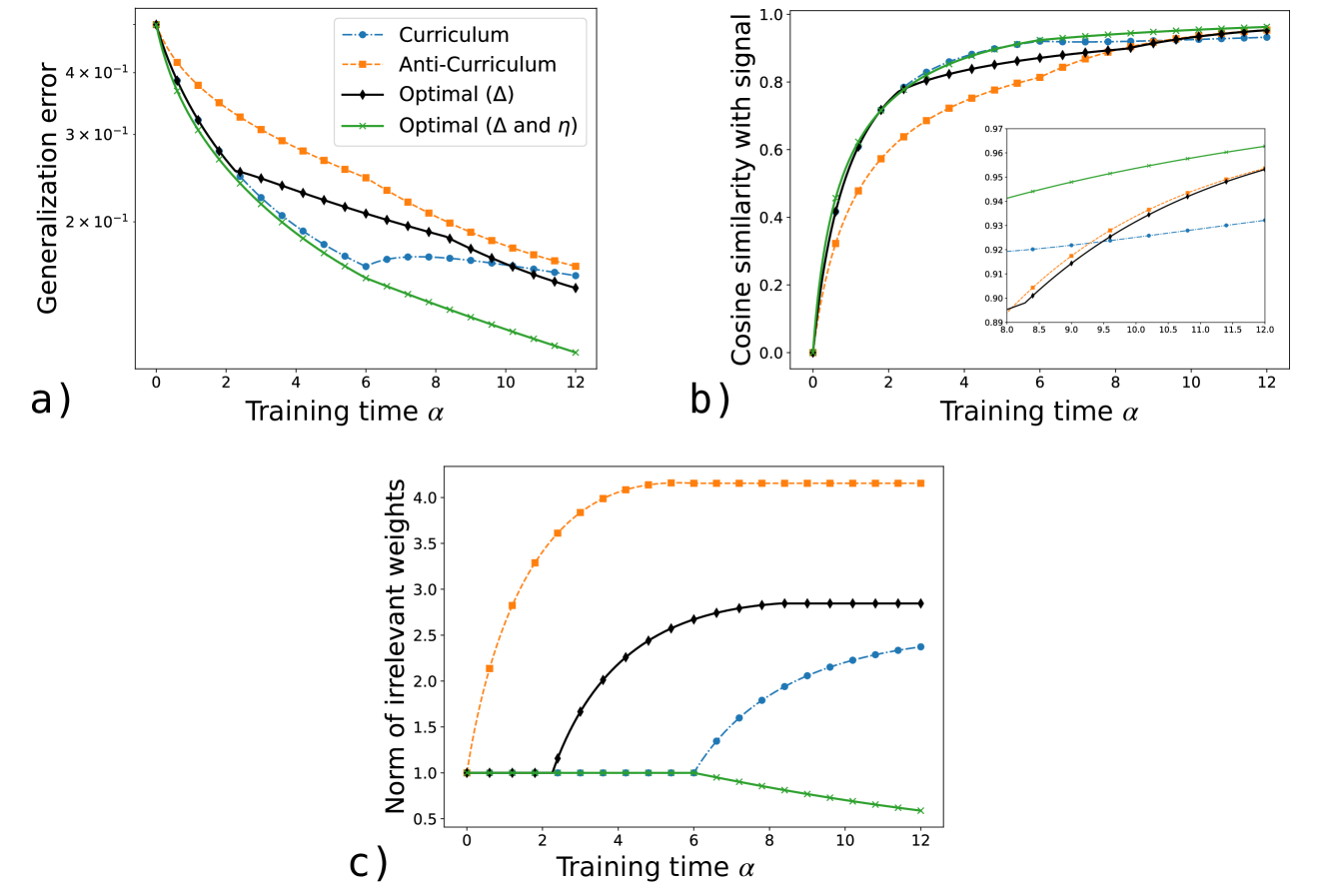
The image contains three subplots (a, b, c) depicting training dynamics for four strategies: Curriculum, Anti-Curriculum, Optimal (Δ), and Optimal (Δ and η). Each subplot tracks a distinct metric (generalization error, cosine similarity, norm of irrelevant weights) against training time (α).
---
### Components/Axes
#### Subplot a)
- **Y-axis**: Generalization error (log scale, 10⁻¹ to 10⁻⁰)
- **X-axis**: Training time α (0 to 12)
- **Legend**:
- Blue dashed: Curriculum
- Orange dashed: Anti-Curriculum
- Black solid: Optimal (Δ)
- Green dashed: Optimal (Δ and η)
#### Subplot b)
- **Y-axis**: Cosine similarity with signal (0 to 1)
- **X-axis**: Training time α (0 to 12)
- **Legend**: Same as subplot a)
- **Inset**: Zoomed view of α=8–12 for finer resolution
#### Subplot c)
- **Y-axis**: Norm of irrelevant weights (0 to 4)
- **X-axis**: Training time α (0 to 12)
- **Legend**: Same as subplot a)
---
### Detailed Analysis
#### Subplot a)
- **Trends**:
- All strategies reduce generalization error over time.
- **Optimal (Δ and η)** (green) decreases fastest, reaching ~2×10⁻¹ by α=12.
- **Anti-Curriculum** (orange) has the slowest decline, ending near 2.5×10⁻¹.
- **Curriculum** (blue) and **Optimal (Δ)** (black) converge at ~2.2×10⁻¹.
#### Subplot b)
- **Trends**:
- All strategies increase cosine similarity, with **Optimal (Δ and η)** (green) achieving ~0.98 by α=12.
- **Anti-Curriculum** (orange) lags, reaching ~0.94.
- Inset confirms sharper divergence after α=8.
#### Subplot c)
- **Trends**:
- **Anti-Curriculum** (orange) shows a sharp rise in irrelevant weights, plateauing at ~4.0.
- **Optimal (Δ and η)** (green) maintains near-zero irrelevant weights.
- **Curriculum** (blue) and **Optimal (Δ)** (black) exhibit moderate increases.
---
### Key Observations
1. **Performance Hierarchy**:
- **Optimal (Δ and η)** outperforms all strategies in generalization error (a), cosine similarity (b), and irrelevant weights (c).
- **Anti-Curriculum** underperforms, particularly in irrelevant weights (c), suggesting poor regularization.
2. **Convergence Patterns**:
- In (a) and (b), Optimal strategies converge faster than Curriculum/Anti-Curriculum.
- In (c), Anti-Curriculum’s irrelevant weights grow unbounded, while Optimal (Δ and η) remains stable.
3. **Divergence in Inset (b)**:
- After α=8, cosine similarity differences between strategies narrow, indicating diminishing returns.
---
### Interpretation
- **Optimal Strategies**: The inclusion of both Δ (optimization) and η (regularization) in the Optimal (Δ and η) strategy appears critical for minimizing generalization error and irrelevant weights while maximizing signal alignment.
- **Anti-Curriculum Pitfalls**: Its increasing irrelevant weights (c) and lower cosine similarity (b) suggest it introduces noise or overfits, undermining performance.
- **Curriculum Trade-offs**: While better than Anti-Curriculum, Curriculum’s slower convergence implies suboptimal hyperparameter tuning compared to Optimal methods.
The data underscores the importance of balancing optimization (Δ) and regularization (η) for robust model training. Anti-Curriculum’s failure to control irrelevant weights highlights the risks of unconstrained learning dynamics.