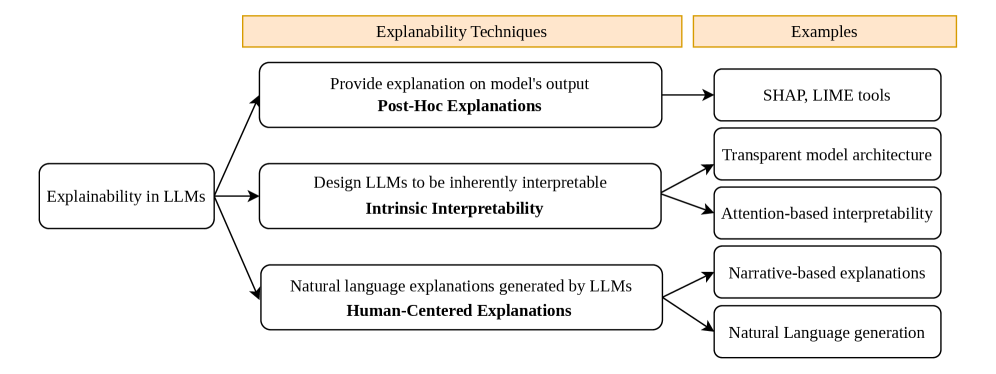
## Diagram: Explainability Techniques in LLMs
### Overview
The image is a diagram illustrating different approaches to explainability in Large Language Models (LLMs). It categorizes explainability techniques into three main types: Post-Hoc Explanations, Intrinsic Interpretability, and Human-Centered Explanations. Each category is further broken down with specific examples.
### Components/Axes
* **Main Node (Left):** "Explainability in LLMs" - This is the central concept.
* **Top Header:** "Explanability Techniques" (orange background)
* **Top Header:** "Examples" (orange background)
* **Category 1:** "Provide explanation on model's output" followed by "Post-Hoc Explanations" (in bold).
* **Category 2:** "Design LLMs to be inherently interpretable" followed by "Intrinsic Interpretability" (in bold).
* **Category 3:** "Natural language explanations generated by LLMs" followed by "Human-Centered Explanations" (in bold).
* **Examples for Post-Hoc Explanations:** "SHAP, LIME tools"
* **Examples for Intrinsic Interpretability:** "Transparent model architecture", "Attention-based interpretability"
* **Examples for Human-Centered Explanations:** "Narrative-based explanations", "Natural Language generation"
* **Arrows:** Arrows indicate the flow from the main node to the categories and from the categories to the examples.
### Detailed Analysis
* **Explainability in LLMs** branches out into three distinct categories:
* **Post-Hoc Explanations:** These techniques provide explanations *after* the model has made a prediction. An example is SHAP and LIME tools.
* **Intrinsic Interpretability:** This approach focuses on designing LLMs to be inherently interpretable. Examples include transparent model architectures and attention-based interpretability.
* **Human-Centered Explanations:** This category involves generating natural language explanations from LLMs. Examples include narrative-based explanations and natural language generation.
### Key Observations
* The diagram clearly separates explainability techniques based on when and how explanations are generated.
* Post-Hoc methods focus on explaining existing models, while Intrinsic Interpretability aims to build explainability into the model's design.
* Human-Centered Explanations emphasize the use of natural language to make explanations more accessible.
### Interpretation
The diagram provides a structured overview of different strategies for achieving explainability in LLMs. It highlights the trade-offs between explaining existing models (Post-Hoc), designing inherently interpretable models (Intrinsic), and generating human-friendly explanations (Human-Centered). The choice of technique depends on the specific application and the desired level of transparency and interpretability. The diagram suggests that explainability is a multifaceted problem with no single solution, and that a combination of techniques may be necessary to achieve comprehensive understanding of LLM behavior.