\n
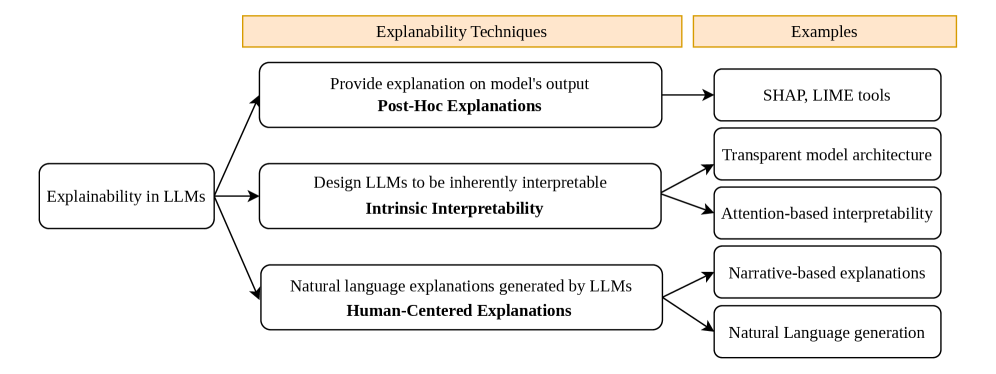
## Diagram: Explainability in LLMs
### Overview
This diagram illustrates the different techniques for achieving explainability in Large Language Models (LLMs). It categorizes these techniques into three main types: Post-Hoc Explanations, Intrinsic Interpretability, and Human-Centered Explanations, and provides examples for each. The diagram uses a flow chart style with boxes and arrows to show the relationship between the main categories and their respective examples.
### Components/Axes
The diagram is divided into two main columns:
* **Left Column:** "Explainability in LLMs" - This serves as the overarching topic.
* **Right Column:** "Examples" - This column lists specific examples of explainability techniques.
The diagram contains three main boxes, each representing a type of explainability technique:
1. "Provide explanation on model's output" - labeled as "Post-Hoc Explanations"
2. "Design LLMs to be inherently interpretable" - labeled as "Intrinsic Interpretability"
3. "Natural language explanations generated by LLMs" - labeled as "Human-Centered Explanations"
Each of these boxes has an arrow pointing to a series of rectangular boxes in the "Examples" column.
### Detailed Analysis or Content Details
The diagram details the following relationships:
* **Post-Hoc Explanations:**
* Example 1: "SHAP, LIME tools"
* Example 2: "Transparent model architecture"
* **Intrinsic Interpretability:**
* Example 1: "Attention-based interpretability"
* **Human-Centered Explanations:**
* Example 1: "Narrative-based explanations"
* Example 2: "Natural Language generation"
The arrows originate from the center of each technique box and point to the corresponding examples. The diagram uses a consistent visual style with rounded rectangles for the main techniques and rectangular boxes for the examples.
### Key Observations
The diagram highlights that explainability in LLMs can be approached from three distinct angles: explaining models *after* they've made a prediction (Post-Hoc), building models that are understandable by design (Intrinsic), and leveraging LLMs to generate explanations in natural language (Human-Centered). The number of examples provided for each technique varies, suggesting differing levels of maturity or research focus in each area.
### Interpretation
The diagram suggests a multi-faceted approach to explainability in LLMs. It acknowledges that there isn't a single "best" method, but rather a spectrum of techniques that can be employed depending on the specific application and model architecture. Post-hoc explanations are useful for understanding existing "black box" models, while intrinsic interpretability focuses on building more transparent models from the ground up. Human-centered explanations aim to make LLM outputs more accessible and understandable to non-technical users. The diagram implies that a combination of these approaches may be necessary to achieve truly comprehensive explainability in LLMs. The diagram does not provide any quantitative data or trends, but rather a conceptual overview of the field.