## Neural Network Diagram: Image Captioning
### Overview
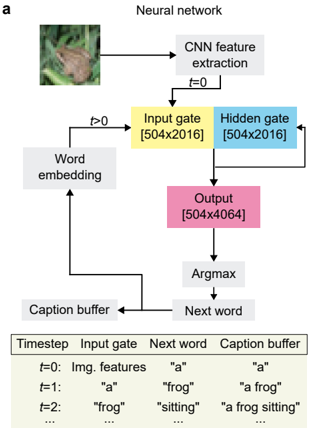
The image is a diagram illustrating a neural network architecture for image captioning. It shows the flow of information from an input image through various processing stages, ultimately generating a descriptive caption. The diagram includes components like CNN feature extraction, input/hidden/output gates, word embedding, and caption buffer. A table at the bottom shows the evolution of the caption over time.
### Components/Axes
* **Title:** Neural network
* **Input:** An image of a frog.
* **CNN feature extraction:** A gray box representing the initial processing of the image.
* **t=0:** Label indicating the initial time step.
* **Input gate:** A yellow box labeled "Input gate [504x2016]".
* **Hidden gate:** A light blue box labeled "Hidden gate [504x2016]".
* **t>0:** Label indicating time steps greater than zero.
* **Word embedding:** A gray box representing the process of converting words into numerical vectors.
* **Output:** A pink box labeled "Output [504x4064]".
* **Argmax:** A gray box representing the selection of the most likely next word.
* **Next word:** A gray box representing the output of the Argmax function.
* **Caption buffer:** A gray box storing the generated caption.
* **Table:**
* Columns: Timestep, Input gate, Next word, Caption buffer
* Rows:
* t=0: Img. features, "a", "a"
* t=1: "a", "frog", "a frog"
* t=2: "frog", "sitting", "a frog sitting"
* ... (ellipsis indicating continuation)
### Detailed Analysis or ### Content Details
* **Image Input:** The process begins with an image, in this case, a frog.
* **CNN Feature Extraction:** The image is processed by a Convolutional Neural Network (CNN) to extract relevant features.
* **Input and Hidden Gates:** The extracted features are fed into the input and hidden gates, both with dimensions [504x2016].
* **Word Embedding:** The word embedding component receives input from the caption buffer and feeds into the input gate.
* **Output:** The output gate, with dimensions [504x4064], produces a representation used to predict the next word.
* **Argmax and Next Word:** The Argmax function selects the most probable next word based on the output.
* **Caption Buffer:** The selected word is added to the caption buffer, which is then fed back into the word embedding component.
* **Table Data:**
* At t=0, the input is image features, the next word is "a", and the caption buffer contains "a".
* At t=1, the input gate receives "a", the next word is "frog", and the caption buffer contains "a frog".
* At t=2, the input gate receives "frog", the next word is "sitting", and the caption buffer contains "a frog sitting".
### Key Observations
* The diagram illustrates a recurrent process where the caption is built iteratively, one word at a time.
* The input and hidden gates have the same dimensions, while the output gate has different dimensions.
* The table shows how the caption evolves over time, starting with "a" and gradually adding more descriptive words.
### Interpretation
The diagram represents a neural network designed to generate captions for images. The CNN extracts visual features, which are then processed through recurrent layers (input, hidden, and output gates) to predict the next word in the caption. The caption buffer stores the generated caption, which is fed back into the network to influence the generation of subsequent words. The table demonstrates the iterative nature of the captioning process, where the caption is refined and expanded with each time step. The dimensions of the gates (504x2016 and 504x4064) likely reflect the size of the feature vectors and the vocabulary used by the network.