\n
## Diagram: Neural Network for Image Captioning
### Overview
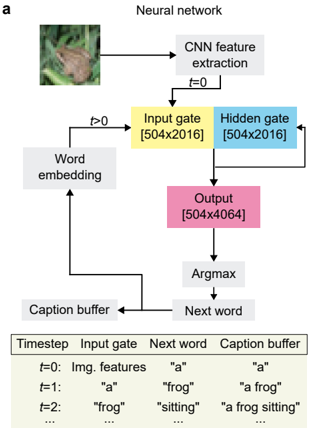
This diagram illustrates the architecture of a neural network designed for image captioning. The network takes an image as input and generates a descriptive caption, step-by-step. It combines Convolutional Neural Networks (CNNs) for feature extraction with recurrent neural network components (Input Gate, Hidden Gate, Output) and word embeddings to produce a coherent textual description.
### Components/Axes
The diagram consists of several key components:
* **Image Input:** A photograph of a frog on foliage (top-left).
* **CNN Feature Extraction:** A rectangular block labeled "CNN feature extraction" (top-center).
* **Input Gate:** A yellow rectangular block labeled "Input gate [504x2016]" (center-left).
* **Hidden Gate:** A blue rectangular block labeled "Hidden gate [504x2016]" (center-right).
* **Output:** A pink rectangular block labeled "Output [504x4064]" (center).
* **Word Embedding:** A gray rectangular block labeled "Word embedding" (left-center).
* **Argmax:** A rectangular block labeled "Argmax" (bottom-center).
* **Caption Buffer:** A rectangular block labeled "Caption buffer" (bottom-left).
* **Next Word:** A rectangular block labeled "Next word" (bottom-right).
* **Timestep Table:** A table below the diagram detailing the input, next word, and caption buffer content at different timesteps (t=0, t=1, t=2).
The diagram also includes directional arrows indicating the flow of information between these components. Timestep is indicated as 't' with a value.
### Detailed Analysis or Content Details
The diagram shows a sequential process.
1. **Image Input:** The process begins with an image of a frog.
2. **CNN Feature Extraction:** The image is fed into a CNN for feature extraction. This occurs at timestep t=0.
3. **Input Gate & Hidden Gate:** The extracted features are then passed to an Input Gate and a Hidden Gate, both with dimensions 504x2016.
4. **Output:** The Input and Hidden Gates feed into an Output layer with dimensions 504x4064.
5. **Argmax & Next Word:** The Output layer is processed by an Argmax function, which selects the most probable next word.
6. **Word Embedding & Caption Buffer:** The selected "Next word" is then embedded and added to the "Caption buffer".
7. **Iteration:** The "Caption buffer" content is fed back into the "Word embedding" block for the next timestep (t>0).
**Timestep Table Content:**
| Timestep | Input Gate | Next Word | Caption Buffer |
| :------- | :------------ | :-------- | :------------- |
| t=0 | Img. features | "a" | "a" |
| t=1 | "a" | "frog" | "a frog" |
| t=2 | "frog" | "sitting" | "a frog sitting" |
The table shows the progression of the caption generation. At t=0, the input is image features, and the first word is "a". At t=1, the input is "a", and the next word is "frog", resulting in the caption "a frog". At t=2, the input is "frog", and the next word is "sitting", resulting in the caption "a frog sitting". The table indicates that the process continues ("...") beyond t=2.
### Key Observations
* The network operates in a sequential manner, generating the caption one word at a time.
* The dimensions of the Input Gate, Hidden Gate, and Output layer are explicitly provided.
* The table demonstrates how the caption is built up incrementally, with each timestep adding a new word to the buffer.
* The diagram highlights the interplay between image features, word embeddings, and recurrent network components.
### Interpretation
This diagram illustrates a common architecture for image captioning, combining the strengths of CNNs for visual understanding with recurrent neural networks (likely LSTMs or GRUs, though not explicitly stated) for sequential data generation. The CNN extracts relevant features from the image, which are then used to initialize the caption generation process. The recurrent network iteratively predicts the next word in the caption, conditioned on the previous words and the image features. The "Caption buffer" acts as the memory of the generated caption, allowing the network to maintain context and produce coherent descriptions. The dimensions provided for the gates and output layer suggest a relatively large model capacity. The table provides a concrete example of how the network generates a caption, demonstrating the step-by-step process of word prediction and caption construction. The diagram is a high-level overview and does not detail the specific implementation of the CNN or recurrent network components.