## Neural Network Diagram: Image Captioning Architecture
### Overview
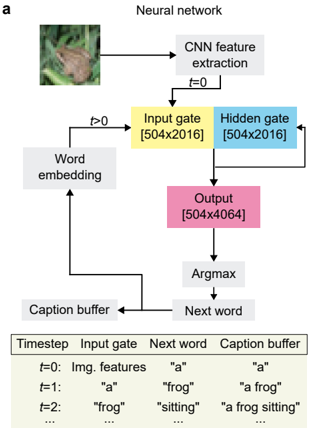
The image is a technical diagram illustrating a recurrent neural network architecture for image captioning. It shows the process of converting an input image into a sequence of words (a caption) through a series of computational steps. The diagram includes a flowchart and an accompanying table that details the process at specific timesteps.
### Components/Axes
The diagram is organized into a flowchart with labeled boxes and directional arrows, and a data table below it.
**Flowchart Components (from top to bottom, left to right):**
1. **Input Image:** A photograph of a frog on a leaf, located in the top-left corner.
2. **CNN feature extraction:** A gray box connected to the input image. An arrow labeled `t=0` points from this box to the "Input gate".
3. **Input gate [504x2016]:** A yellow box. It receives input from "CNN feature extraction" (at `t=0`) and from "Word embedding" (for `t>0`).
4. **Hidden gate [504x2016]:** A blue box, positioned to the right of the "Input gate". It receives input from the "Input gate".
5. **Output [504x4064]:** A pink box below the "Hidden gate". It receives input from the "Hidden gate".
6. **Argmax:** A gray box below the "Output" box.
7. **Next word:** A gray box below "Argmax".
8. **Caption buffer:** A gray box to the left of "Next word". It receives input from "Next word" and has an arrow pointing back to the "Word embedding" block.
9. **Word embedding:** A gray box to the left of the "Input gate". It receives input from the "Caption buffer".
**Data Table:**
Located at the bottom of the image. It has four columns:
* **Timestep:** Lists `t=0`, `t=1`, `t=2`, and `...`.
* **Input gate:** Describes the input to the gate at each step.
* **Next word:** Shows the word generated at that step.
* **Caption buffer:** Shows the accumulated caption text.
### Detailed Analysis
**Flowchart Process:**
The process is recurrent, operating over discrete timesteps (`t`).
* **At t=0:** The "CNN feature extraction" block processes the input image. Its output (image features) is fed directly into the "Input gate". The "Next word" generated is "a", which is stored in the "Caption buffer".
* **For t>0:** The process becomes recurrent. The current content of the "Caption buffer" is fed into the "Word embedding" block. The output of the "Word embedding" is then fed into the "Input gate". The "Hidden gate" processes information from the "Input gate". The "Output" layer produces a large vector, from which "Argmax" selects the most probable "Next word". This new word is appended to the "Caption buffer", and the loop continues.
**Table Data Transcription:**
| Timestep | Input gate | Next word | Caption buffer |
| :------- | :------------------ | :-------- | :----------------- |
| t=0 | Img. features | "a" | "a" |
| t=1 | "a" | "frog" | "a frog" |
| t=2 | "frog" | "sitting" | "a frog sitting" |
| ... | ... | ... | ... |
**Dimensions Noted:**
* Input gate: `[504x2016]`
* Hidden gate: `[504x2016]`
* Output: `[504x4064]`
### Key Observations
1. **Hybrid Architecture:** The model combines a Convolutional Neural Network (CNN) for visual feature extraction with a recurrent network (likely an LSTM or GRU, given the "gate" terminology) for language generation.
2. **Sequential Generation:** The caption is generated word-by-word in an autoregressive manner, where each new word depends on the previously generated words (stored in the caption buffer).
3. **Stateful Process:** The "Hidden gate" maintains a state that carries information across timesteps, which is crucial for generating coherent sentences.
4. **Fixed Input Size:** The dimensions `[504x2016]` suggest the CNN outputs a fixed-size feature vector (of length 2016) for each of 504 spatial regions or time steps, which is then processed by the recurrent network.
### Interpretation
This diagram explains the "how" behind an AI system that can look at a picture and describe it in natural language. It demonstrates a classic encoder-decoder framework:
* **Encoder (CNN):** Translates the raw pixels of the frog image into a abstract, numerical representation ("Img. features").
* **Decoder (Recurrent Network):** Translates that numerical representation into a sequence of words, using its internal memory (the hidden state and caption buffer) to ensure the sentence makes grammatical and contextual sense.
The table provides a concrete example, showing the model's "thought process." It starts with the generic article "a," then identifies the main subject "frog," and finally adds a descriptive action "sitting." This step-by-step generation is fundamental to how modern image captioning and many other sequence-to-sequence AI models function. The architecture is designed to bridge the gap between computer vision (understanding images) and natural language processing (generating text).