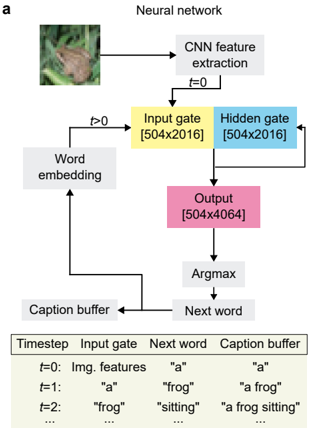
## Diagram: Neural Network Architecture for Image Captioning
### Overview
The diagram illustrates a recurrent neural network (RNN) architecture for generating image captions. It combines convolutional neural network (CNN) feature extraction with sequential processing via gates and word embeddings. The process iteratively builds a caption by selecting the next word at each timestep based on the current state of the network.
### Components/Axes
1. **Main Diagram Components**:
- **CNN Feature Extraction**: Processes the input image (top-left).
- **Input Gate** (`[504x2016]`): Receives CNN features at `t=0`; later takes word embeddings (`t>0`).
- **Hidden Gate** (`[504x2016]`): Processes inputs via recurrent connections.
- **Output** (`[504x4064]`): Produces logits for the next word prediction.
- **Argmax**: Selects the most probable word from the output.
- **Caption Buffer**: Stores the generated caption incrementally.
- **Next Word**: Output of Argmax, fed back into the network.
- **Word Embedding**: Maps words to vector representations for input to the gates.
2. **Table Structure**:
- **Headers**: `Timestep`, `Input gate`, `Next word`, `Caption buffer`.
- **Rows**:
- `t=0`: `Img. features` → `"a"` → `"a"`.
- `t=1`: `"a"` → `"frog"` → `"a frog"`.
- `t=2`: `"frog"` → `"sitting"` → `"a frog sitting"`.
- `...`: Continues iteratively.
### Detailed Analysis
- **Flow Direction**:
- At `t=0`, CNN features are input to the Input Gate. The first word `"a"` is selected via Argmax and added to the Caption Buffer.
- For `t>0`, the previous word (e.g., `"a"`) is embedded and fed into the Input Gate. The Hidden Gate processes this alongside the current state to predict the next word (e.g., `"frog"` at `t=1`).
- The Caption Buffer accumulates words sequentially (e.g., `"a frog sitting"` at `t=2`).
- **Dimensionality**:
- Input/Output Gates: `[504x2016]` (likely word embedding dimensions).
- Output Layer: `[504x4064]` (vocabulary size of ~4064 words).
### Key Observations
1. **Sequential Generation**: The caption is built word-by-word, with each step depending on the prior state.
2. **Recurrent Loop**: The Caption Buffer and Next Word create a feedback loop, enabling context-aware predictions.
3. **Dimensional Consistency**: Input/Output Gates share the same dimensions, suggesting shared weight matrices in the RNN.
### Interpretation
This architecture demonstrates a **seq2seq** (sequence-to-sequence) model with attention-like mechanisms. The CNN extracts spatial features, while the RNN handles temporal dependencies in the caption. The use of Argmax for word selection simplifies decoding but may limit diversity in generated captions. The increasing length of the Caption Buffer (`"a"` → `"a frog"` → `"a frog sitting"`) highlights the model's incremental text generation. The shared dimensions between gates imply efficient parameter reuse, critical for handling variable-length sequences. The model's reliance on fixed vocabulary size (4064 words) suggests a trade-off between coverage and computational efficiency.