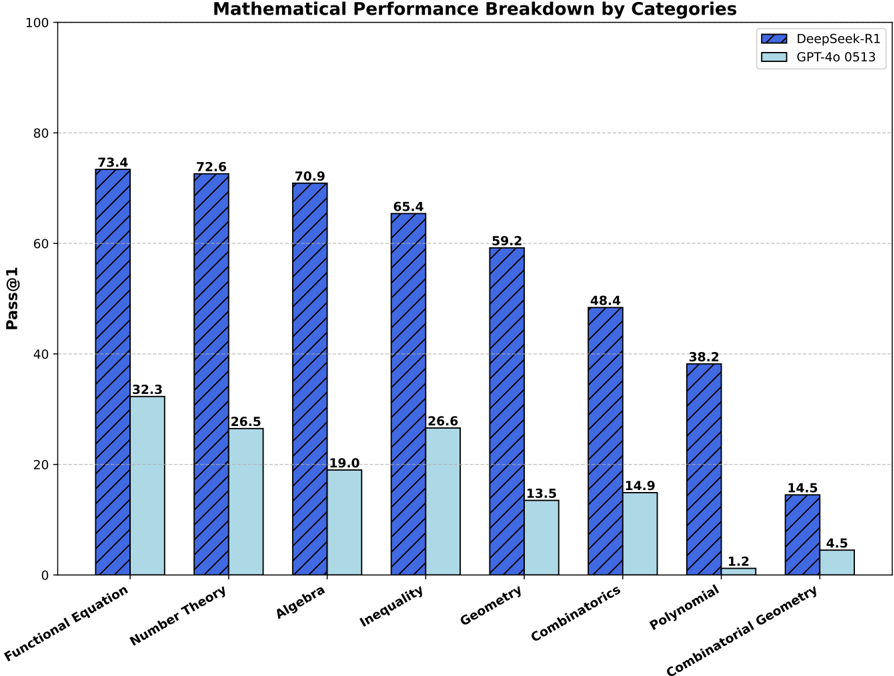
## Bar Chart: Mathematical Performance Breakdown by Categories
### Overview
The chart compares the performance of two AI models, **DeepSeek-R1** (blue diagonal-hatched bars) and **GPT-4o 0513** (light blue solid bars), across eight mathematical categories. Performance is measured as "Pass@1" (percentage of correct answers) on a scale from 0 to 100.
### Components/Axes
- **X-axis (Categories)**:
Functional Equation, Number Theory, Algebra, Inequality, Geometry, Combinatorics, Polynomial, Combinatorial Geometry.
- **Y-axis (Pass@1)**:
Scale from 0 to 100, with gridlines at 20, 40, 60, 80.
- **Legend**:
- Top-right corner.
- **DeepSeek-R1**: Blue diagonal-hatched bars.
- **GPT-4o 0513**: Light blue solid bars.
### Detailed Analysis
#### Categories and Values
1. **Functional Equation**
- DeepSeek-R1: 73.4
- GPT-4o 0513: 32.3
2. **Number Theory**
- DeepSeek-R1: 72.6
- GPT-4o 0513: 26.5
3. **Algebra**
- DeepSeek-R1: 70.9
- GPT-4o 0513: 19.0
4. **Inequality**
- DeepSeek-R1: 65.4
- GPT-4o 0513: 26.6
5. **Geometry**
- DeepSeek-R1: 59.2
- GPT-4o 0513: 13.5
6. **Combinatorics**
- DeepSeek-R1: 48.4
- GPT-4o 0513: 14.9
7. **Polynomial**
- DeepSeek-R1: 38.2
- GPT-4o 0513: 1.2
8. **Combinatorial Geometry**
- DeepSeek-R1: 14.5
- GPT-4o 0513: 4.5
### Key Observations
- **Dominance of DeepSeek-R1**:
DeepSeek-R1 outperforms GPT-4o 0513 in **all categories**, with performance gaps ranging from **23.8%** (Combinatorial Geometry) to **41.1%** (Functional Equation).
- **Largest Gaps**:
- Functional Equation: 73.4 vs. 32.3
- Number Theory: 72.6 vs. 26.5
- **Smallest Gaps**:
- Combinatorial Geometry: 14.5 vs. 4.5
- **GPT-4o 0513 Weaknesses**:
Particularly poor performance in **Polynomial** (1.2%) and **Geometry** (13.5%).
### Interpretation
The data suggests **DeepSeek-R1 has significantly stronger mathematical reasoning capabilities** than GPT-4o 0513 across diverse domains. The consistent superiority of DeepSeek-R1 implies:
1. **Architectural or Training Advantages**: DeepSeek-R1 may be optimized for mathematical problem-solving.
2. **Data Quality**: DeepSeek-R1’s training data might include more high-quality mathematical examples.
3. **Generalization Limitations**: GPT-4o 0513 struggles with abstract or specialized topics (e.g., Polynomial, Combinatorial Geometry), indicating potential gaps in its training corpus or model design.
The stark contrast in **Polynomial** performance (38.2% vs. 1.2%) highlights a critical weakness in GPT-4o 0513, while DeepSeek-R1’s near-parity in **Combinatorial Geometry** (14.5% vs. 4.5%) suggests it handles niche topics better.
### Spatial Grounding
- Legend: Top-right corner, clearly associating colors/hatches with models.
- Bar Groups: Categories are evenly spaced along the x-axis, with bars clustered by model.
- Y-axis: Gridlines aid in estimating values between labeled ticks.
### Trend Verification
- **DeepSeek-R1**: Slopes downward slightly from Functional Equation (73.4) to Combinatorial Geometry (14.5), indicating diminishing performance in more abstract categories.
- **GPT-4o 0513**: Shows erratic trends, with sharp drops in Polynomial (1.2%) and Geometry (13.5%), suggesting domain-specific failures.
### Notable Anomalies
- **GPT-4o 0513’s Polynomial Collapse**: A 1.2% score in Polynomial is an outlier, far below its other low scores (e.g., 19.0% in Algebra).
- **Combinatorial Geometry Parity**: Both models perform poorly here, but DeepSeek-R1’s 14.5% is still 3x better than GPT-4o’s 4.5%.
This chart underscores the importance of specialized training for mathematical AI systems and highlights areas where current models still lag behind human expertise.