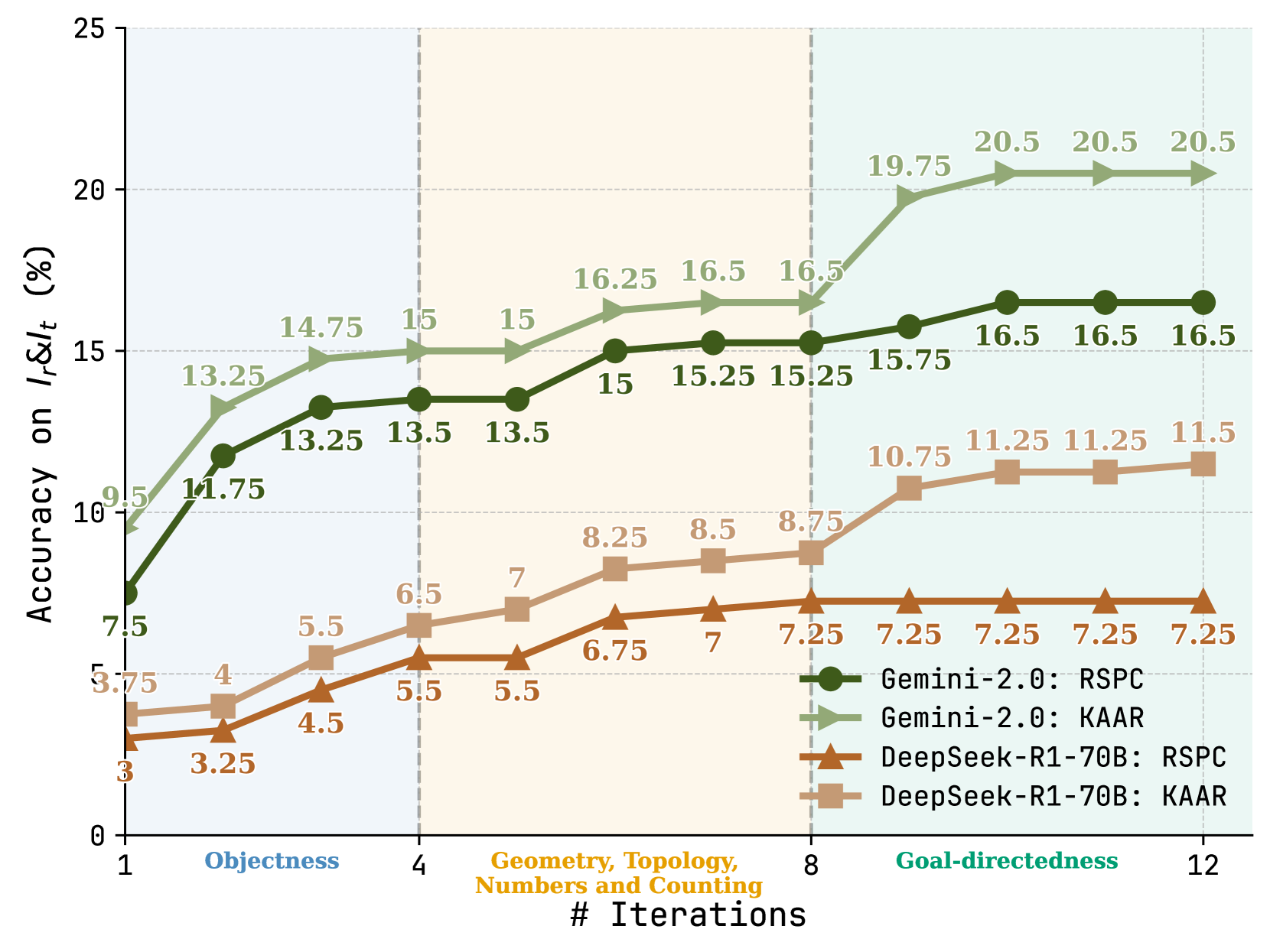
\n
## Line Chart: Accuracy vs. Iterations for Different Models
### Overview
This line chart displays the accuracy of four different models (Gemini-2.0 with RSPC, Gemini-2.0 with KAAR, DeepSeek-R1-70B with RSPC, and DeepSeek-R1-70B with KAAR) across 12 iterations, categorized by three distinct tasks: Objectness, Geometry/Topology/Numbers & Counting, and Goal-directedness. The y-axis represents accuracy on *I&L<sub>t</sub>* (%), while the x-axis represents the number of iterations.
### Components/Axes
* **X-axis:** "# Iterations" - Scale from 1 to 12. Markers at 1, 4, 8, and 12.
* **Y-axis:** "Accuracy on *I&L<sub>t</sub>* (%)" - Scale from 0 to 25. Markers at 0, 5, 10, 15, 20, and 25.
* **Legend:** Located in the bottom-right corner.
* Black Circle: Gemini-2.0: RSPC
* Gray Circle: Gemini-2.0: KAAR
* Brown Triangle: DeepSeek-R1-70B: RSPC
* Dark Teal Square: DeepSeek-R1-70B: KAAR
* **Task Categories:** The x-axis is divided into three sections, visually separated by vertical dashed lines:
* "Objectness" (Iterations 1-4)
* "Geometry, Topology, Numbers and Counting" (Iterations 4-8)
* "Goal-directedness" (Iterations 8-12)
### Detailed Analysis
Here's a breakdown of the data for each model and task, with approximate values:
**1. Gemini-2.0: RSPC (Black Circle)**
* **Objectness (1-4 iterations):** Starts at approximately 9.5% at iteration 1, increases to 13.25% at iteration 2, 14.75% at iteration 3, and plateaus at 15% at iteration 4.
* **Geometry/Topology/Numbers & Counting (4-8 iterations):** Remains at 15% until iteration 6, then decreases slightly to 15.25% at iteration 7, and 16.5% at iteration 8.
* **Goal-directedness (8-12 iterations):** Increases sharply to 19.75% at iteration 9, then plateaus at approximately 20.5% for iterations 10, 11, and 12.
**2. Gemini-2.0: KAAR (Gray Circle)**
* **Objectness (1-4 iterations):** Starts at approximately 3.75% at iteration 1, increases to 11.75% at iteration 2, 13.25% at iteration 3, and 13.5% at iteration 4.
* **Geometry/Topology/Numbers & Counting (4-8 iterations):** Increases to 15% at iteration 5, then remains relatively stable at 15.25% at iteration 6, 15.25% at iteration 7, and 15.25% at iteration 8.
* **Goal-directedness (8-12 iterations):** Increases to 15.75% at iteration 9, then plateaus at approximately 16.5% for iterations 10, 11, and 12.
**3. DeepSeek-R1-70B: RSPC (Brown Triangle)**
* **Objectness (1-4 iterations):** Starts at approximately 4% at iteration 1, increases to 5.5% at iteration 2, 6.5% at iteration 3, and 7% at iteration 4.
* **Geometry/Topology/Numbers & Counting (4-8 iterations):** Increases to 8.25% at iteration 5, 8.5% at iteration 6, 8.5% at iteration 7, and 8.75% at iteration 8.
* **Goal-directedness (8-12 iterations):** Increases to 10.75% at iteration 9, 11.25% at iteration 10, 11.25% at iteration 11, and 11.5% at iteration 12.
**4. DeepSeek-R1-70B: KAAR (Dark Teal Square)**
* **Objectness (1-4 iterations):** Starts at approximately 3.25% at iteration 1, increases to 4.5% at iteration 2, 5.5% at iteration 3, and 5.5% at iteration 4.
* **Geometry/Topology/Numbers & Counting (4-8 iterations):** Increases to 6.75% at iteration 5, 7% at iteration 6, 7.25% at iteration 7, and 7.25% at iteration 8.
* **Goal-directedness (8-12 iterations):** Increases to 7.25% at iteration 9, 7.25% at iteration 10, 7.25% at iteration 11, and 7.25% at iteration 12.
### Key Observations
* **Gemini-2.0: RSPC** consistently outperforms all other models across all tasks and iterations.
* **Gemini-2.0: KAAR** generally performs better than the DeepSeek models, but lags behind the RSPC version of Gemini-2.0.
* **DeepSeek-R1-70B: RSPC** performs better than **DeepSeek-R1-70B: KAAR**.
* The most significant performance gains for all models occur during the "Goal-directedness" task (iterations 8-12).
* The "Objectness" task shows the least amount of improvement across iterations.
* The accuracy curves for Gemini-2.0: RSPC and Gemini-2.0: KAAR flatten out after a certain number of iterations, suggesting diminishing returns.
### Interpretation
The data suggests that Gemini-2.0, particularly when paired with RSPC, is the most effective model for these tasks. The substantial increase in accuracy during the "Goal-directedness" phase indicates that these models are better equipped to handle tasks requiring more complex reasoning and planning. The relatively low accuracy scores for the DeepSeek models suggest they may require further training or architectural improvements to achieve comparable performance. The flattening of the curves for Gemini-2.0 models implies that further iterations may not yield significant improvements, and resources could be better allocated to exploring alternative approaches or focusing on more challenging tasks. The difference between RSPC and KAAR suggests that the choice of the augmentation technique significantly impacts performance. The consistent ranking of the models across all tasks suggests that the observed differences are not task-specific anomalies.