\n
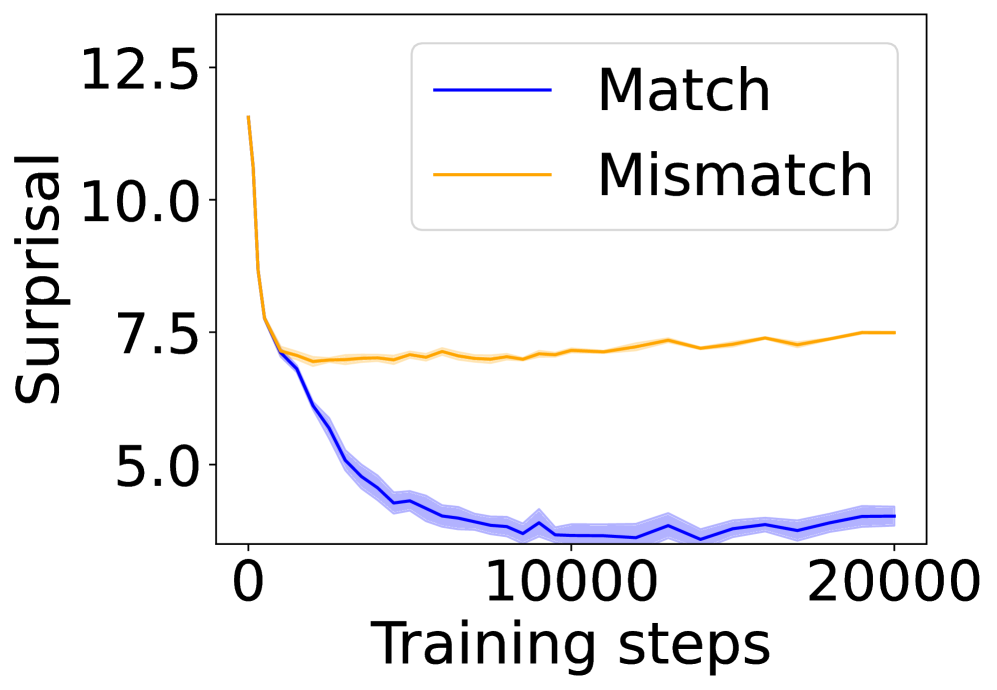
## Line Chart: Surprisal vs. Training Steps
### Overview
The image presents a line chart illustrating the relationship between "Surprisal" (y-axis) and "Training steps" (x-axis). Two data series are plotted: one representing "Match" and the other "Mismatch" conditions. The chart appears to track the evolution of surprisal during a training process.
### Components/Axes
* **X-axis:** "Training steps", ranging from approximately 0 to 20000. The axis is linearly scaled.
* **Y-axis:** "Surprisal", ranging from approximately 4.5 to 12.5. The axis is linearly scaled.
* **Legend:** Located in the top-right corner of the chart.
* "Match" - represented by a dark blue line.
* "Mismatch" - represented by a golden-yellow line.
### Detailed Analysis
**Match (Dark Blue Line):**
The "Match" line begins at approximately 5.2 and exhibits a steep downward trend initially, decreasing rapidly to a minimum of around 4.6 at approximately 5000 training steps. After this initial drop, the line fluctuates around a value of approximately 4.6-5.0, with minor oscillations, until 20000 training steps.
**Mismatch (Golden-Yellow Line):**
The "Mismatch" line starts at approximately 7.7 and shows a slight decreasing trend initially, leveling off to a relatively stable value around 7.5-7.8. There are minor fluctuations throughout the training process, but the overall trend is relatively flat.
**Data Points (Approximate):**
| Training Steps | Match Surprisal | Mismatch Surprisal |
|----------------|-----------------|--------------------|
| 0 | 5.2 | 7.7 |
| 5000 | 4.6 | 7.6 |
| 10000 | 4.8 | 7.7 |
| 15000 | 4.7 | 7.6 |
| 20000 | 4.9 | 7.8 |
### Key Observations
* The "Match" condition exhibits a significant decrease in surprisal during the initial training phase, suggesting rapid learning or adaptation.
* The "Mismatch" condition maintains a relatively constant level of surprisal throughout the training process, indicating limited learning or adaptation.
* The "Match" surprisal consistently remains lower than the "Mismatch" surprisal across all training steps.
* The difference in surprisal between the two conditions appears to remain relatively constant after the initial drop in the "Match" condition.
### Interpretation
The chart suggests that the training process is more effective when there is a "Match" between the input and the expected output. The rapid decrease in surprisal for the "Match" condition indicates that the model is quickly learning to predict or represent the matched data. Conversely, the stable surprisal for the "Mismatch" condition suggests that the model is struggling to learn from mismatched data, potentially due to inherent inconsistencies or difficulties in the learning task. The consistent difference in surprisal between the two conditions highlights the importance of data quality and alignment in the training process. The chart could be illustrating the performance of a model trained on correctly paired data versus incorrectly paired data. The model learns quickly when the data is a "Match" and fails to learn when the data is a "Mismatch".