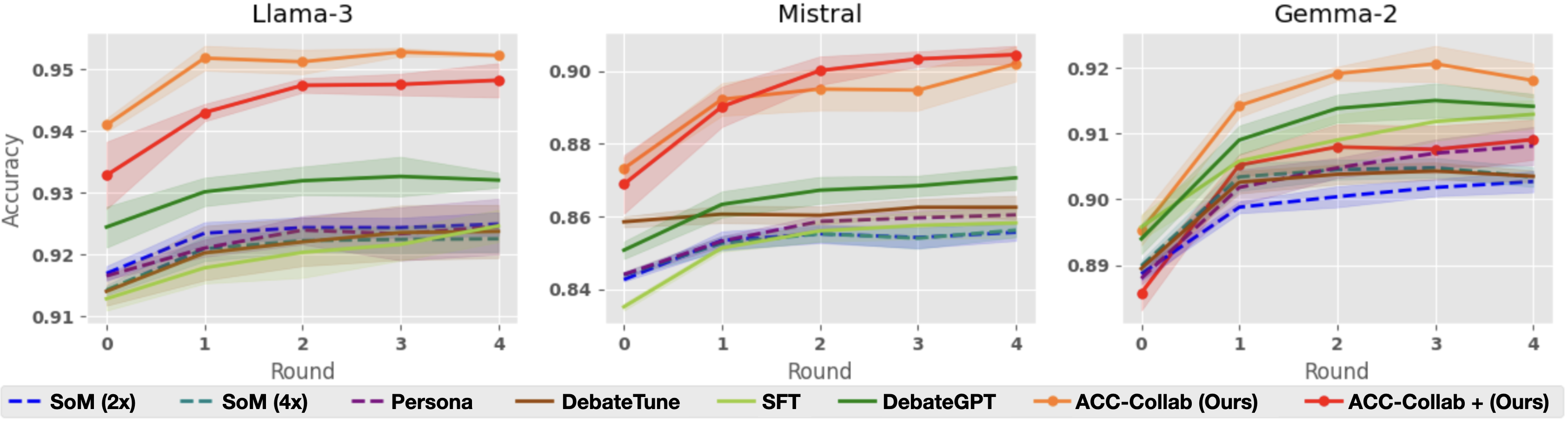
## Line Charts: Model Accuracy vs. Round
### Overview
The image presents three line charts comparing the accuracy of different models (Llama-3, Mistral, and Gemma-2) across multiple rounds of interaction or training. Each chart displays the performance of several methods, including "SoM (2x)", "SoM (4x)", "Persona", "DebateTune", "SFT", "DebateGPT", "ACC-Collab (Ours)", and "ACC-Collab + (Ours)". The x-axis represents the round number (0 to 4), and the y-axis represents the accuracy score. Each line represents a different method, and shaded areas around the lines indicate the confidence interval or variability in the results.
### Components/Axes
* **Titles:** The charts are titled "Llama-3" (top-left), "Mistral" (top-center), and "Gemma-2" (top-right).
* **X-axis:** Labeled "Round", with markers at 0, 1, 2, 3, and 4.
* **Y-axis:** Labeled "Accuracy", with different scales for each chart:
* Llama-3: 0.91 to 0.95
* Mistral: 0.84 to 0.90
* Gemma-2: 0.89 to 0.92
* **Legend:** Located at the bottom of the image, mapping line colors/styles to methods:
* Blue dashed line: SoM (2x)
* Teal dashed line: SoM (4x)
* Purple dashed line: Persona
* Brown solid line: DebateTune
* Light Green solid line: SFT
* Dark Green solid line: DebateGPT
* Orange solid line: ACC-Collab (Ours)
* Red solid line: ACC-Collab + (Ours)
### Detailed Analysis
#### Llama-3 Chart
* **ACC-Collab + (Ours) (Red):** Starts at approximately 0.933 at round 0, increases to about 0.947 by round 1, and then plateaus around 0.948-0.949 for rounds 2-4.
* **ACC-Collab (Ours) (Orange):** Starts at approximately 0.941 at round 0, increases to about 0.952 by round 1, and then plateaus around 0.953-0.954 for rounds 2-4.
* **DebateGPT (Dark Green):** Starts at approximately 0.916 at round 0, increases to about 0.930 by round 1, and then plateaus around 0.932-0.933 for rounds 2-4.
* **SoM (2x) (Blue Dashed):** Starts at approximately 0.917 at round 0, increases to about 0.924 by round 1, and then plateaus around 0.925-0.926 for rounds 2-4.
* **SoM (4x) (Teal Dashed):** Starts at approximately 0.918 at round 0, increases to about 0.922 by round 1, and then plateaus around 0.923-0.924 for rounds 2-4.
* **Persona (Purple Dashed):** Starts at approximately 0.918 at round 0, increases to about 0.924 by round 1, and then plateaus around 0.925-0.926 for rounds 2-4.
* **DebateTune (Brown):** Starts at approximately 0.916 at round 0, increases to about 0.920 by round 1, and then plateaus around 0.921-0.922 for rounds 2-4.
* **SFT (Light Green):** Starts at approximately 0.914 at round 0, increases to about 0.921 by round 1, and then plateaus around 0.922-0.923 for rounds 2-4.
#### Mistral Chart
* **ACC-Collab + (Ours) (Red):** Starts at approximately 0.872 at round 0, increases to about 0.899 by round 2, and then plateaus around 0.901-0.902 for rounds 3-4.
* **ACC-Collab (Ours) (Orange):** Starts at approximately 0.877 at round 0, increases to about 0.895 by round 2, and then plateaus around 0.896-0.897 for rounds 3-4.
* **DebateGPT (Dark Green):** Starts at approximately 0.859 at round 0, increases to about 0.871 by round 2, and then plateaus around 0.872-0.873 for rounds 3-4.
* **SoM (2x) (Blue Dashed):** Starts at approximately 0.842 at round 0, increases to about 0.857 by round 2, and then plateaus around 0.858-0.859 for rounds 3-4.
* **SoM (4x) (Teal Dashed):** Starts at approximately 0.860 at round 0, increases to about 0.863 by round 2, and then plateaus around 0.864-0.865 for rounds 3-4.
* **Persona (Purple Dashed):** Starts at approximately 0.860 at round 0, increases to about 0.863 by round 2, and then plateaus around 0.864-0.865 for rounds 3-4.
* **DebateTune (Brown):** Starts at approximately 0.859 at round 0, increases to about 0.860 by round 2, and then plateaus around 0.861-0.862 for rounds 3-4.
* **SFT (Light Green):** Starts at approximately 0.837 at round 0, increases to about 0.857 by round 2, and then plateaus around 0.858-0.859 for rounds 3-4.
#### Gemma-2 Chart
* **ACC-Collab + (Ours) (Red):** Starts at approximately 0.890 at round 0, increases to about 0.906 by round 1, and then plateaus around 0.907-0.908 for rounds 2-4.
* **ACC-Collab (Ours) (Orange):** Starts at approximately 0.895 at round 0, increases to about 0.918 by round 2, and then decreases to about 0.916 for round 4.
* **DebateGPT (Dark Green):** Starts at approximately 0.898 at round 0, increases to about 0.913 by round 2, and then plateaus around 0.914-0.915 for rounds 3-4.
* **SoM (2x) (Blue Dashed):** Starts at approximately 0.892 at round 0, increases to about 0.903 by round 2, and then plateaus around 0.904-0.905 for rounds 3-4.
* **SoM (4x) (Teal Dashed):** Starts at approximately 0.901 at round 0, increases to about 0.905 by round 2, and then plateaus around 0.906-0.907 for rounds 3-4.
* **Persona (Purple Dashed):** Starts at approximately 0.890 at round 0, increases to about 0.908 by round 2, and then plateaus around 0.909-0.910 for rounds 3-4.
* **DebateTune (Brown):** Starts at approximately 0.888 at round 0, increases to about 0.904 by round 2, and then plateaus around 0.905-0.906 for rounds 3-4.
* **SFT (Light Green):** Starts at approximately 0.899 at round 0, increases to about 0.909 by round 2, and then plateaus around 0.910-0.911 for rounds 3-4.
### Key Observations
* **Initial Improvement:** Most methods show a significant increase in accuracy from round 0 to round 1 or 2.
* **Plateau Effect:** After the initial improvement, the accuracy tends to plateau, indicating diminishing returns from further rounds.
* **ACC-Collab Superiority:** The "ACC-Collab (Ours)" and "ACC-Collab + (Ours)" methods generally outperform the other methods across all three models.
* **Model-Specific Performance:** The absolute accuracy values differ across the models, with Llama-3 generally achieving higher accuracy scores than Mistral and Gemma-2.
### Interpretation
The charts demonstrate the impact of different methods on the accuracy of three language models (Llama-3, Mistral, and Gemma-2) over multiple rounds. The "ACC-Collab" methods appear to be the most effective in improving accuracy, suggesting that collaborative approaches enhance model performance. The plateau effect observed after a few rounds indicates that the models may reach a point of diminishing returns with the given methods and data. The differences in absolute accuracy across the models highlight the inherent variations in their architectures and training data. The shaded areas around the lines provide insights into the variability of the results, which is crucial for assessing the robustness of the methods.