TECHNICAL ASSET FINGERPRINT
01be408307e6b3792f4f9741
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
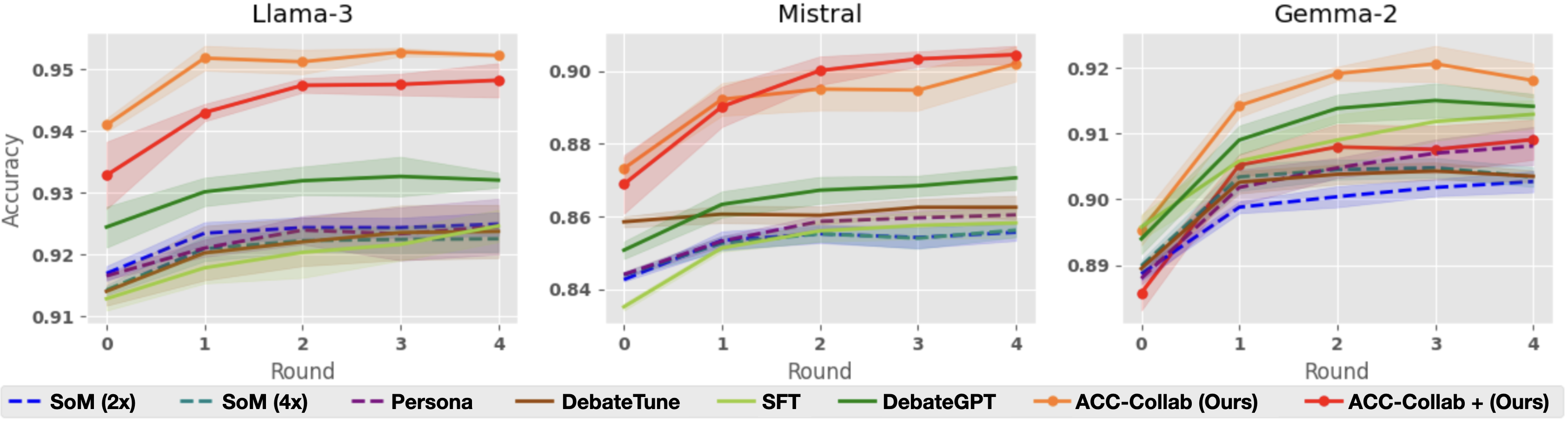
## Line Chart: Accuracy vs. Round for Different Models and Training Methods
### Overview
The image presents three line charts, each displaying the accuracy of different language models (Llama-3, Mistral, and Gemma-2) across four rounds of evaluation. Each chart includes multiple lines representing different training methods or configurations applied to the respective model. The y-axis represents accuracy, and the x-axis represents the round number.
### Components/Axes
* **X-axis:** "Round" with values 0, 1, 2, 3, and 4.
* **Y-axis:** "Accuracy" with a scale ranging from approximately 0.84 to 0.95.
* **Models (Charts):** Llama-3, Mistral, Gemma-2.
* **Training Methods/Configurations (Legend):**
* SoM (2x) - Dashed dark blue line
* SoM (4x) - Dashed purple line
* Persona - Solid purple line
* DebateTune - Solid green line
* SFT - Solid light green line
* DebateGPT - Solid dark green line
* ACC-Collab (Ours) - Solid orange line
* ACC-Collab + (Ours) - Dashed orange line
### Detailed Analysis or Content Details
**Llama-3 Chart:**
* **ACC-Collab (Ours):** Starts at approximately 0.945 accuracy at round 0, increases slightly to around 0.947 at round 1, then decreases to approximately 0.943 at round 4.
* **ACC-Collab + (Ours):** Starts at approximately 0.925 accuracy at round 0, increases to around 0.935 at round 1, then remains relatively stable around 0.932-0.934 for rounds 2-4.
* **SoM (2x):** Starts at approximately 0.922 accuracy at round 0, increases to around 0.926 at round 1, then remains relatively stable around 0.924-0.927 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.918 accuracy at round 0, increases to around 0.922 at round 1, then remains relatively stable around 0.920-0.923 for rounds 2-4.
* **Persona:** Starts at approximately 0.920 accuracy at round 0, increases to around 0.924 at round 1, then remains relatively stable around 0.922-0.925 for rounds 2-4.
* **DebateTune:** Starts at approximately 0.924 accuracy at round 0, increases to around 0.928 at round 1, then remains relatively stable around 0.926-0.929 for rounds 2-4.
* **SFT:** Starts at approximately 0.922 accuracy at round 0, increases to around 0.926 at round 1, then remains relatively stable around 0.924-0.927 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.920 accuracy at round 0, increases to around 0.924 at round 1, then remains relatively stable around 0.922-0.925 for rounds 2-4.
**Mistral Chart:**
* **ACC-Collab (Ours):** Starts at approximately 0.885 accuracy at round 0, increases to around 0.90 at round 1, then decreases to approximately 0.895 at round 4.
* **ACC-Collab + (Ours):** Starts at approximately 0.855 accuracy at round 0, increases to around 0.87 at round 1, then remains relatively stable around 0.865-0.875 for rounds 2-4.
* **SoM (2x):** Starts at approximately 0.850 accuracy at round 0, increases to around 0.860 at round 1, then remains relatively stable around 0.855-0.865 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.840 accuracy at round 0, increases to around 0.850 at round 1, then remains relatively stable around 0.845-0.855 for rounds 2-4.
* **Persona:** Starts at approximately 0.845 accuracy at round 0, increases to around 0.855 at round 1, then remains relatively stable around 0.850-0.855 for rounds 2-4.
* **DebateTune:** Starts at approximately 0.855 accuracy at round 0, increases to around 0.865 at round 1, then remains relatively stable around 0.860-0.865 for rounds 2-4.
* **SFT:** Starts at approximately 0.850 accuracy at round 0, increases to around 0.860 at round 1, then remains relatively stable around 0.855-0.865 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.845 accuracy at round 0, increases to around 0.855 at round 1, then remains relatively stable around 0.850-0.855 for rounds 2-4.
**Gemma-2 Chart:**
* **ACC-Collab (Ours):** Starts at approximately 0.915 accuracy at round 0, decreases to around 0.910 at round 1, then remains relatively stable around 0.912-0.915 for rounds 2-4.
* **ACC-Collab + (Ours):** Starts at approximately 0.895 accuracy at round 0, increases to around 0.905 at round 1, then remains relatively stable around 0.900-0.905 for rounds 2-4.
* **SoM (2x):** Starts at approximately 0.890 accuracy at round 0, increases to around 0.900 at round 1, then remains relatively stable around 0.895-0.900 for rounds 2-4.
* **SoM (4x):** Starts at approximately 0.885 accuracy at round 0, increases to around 0.895 at round 1, then remains relatively stable around 0.890-0.895 for rounds 2-4.
* **Persona:** Starts at approximately 0.890 accuracy at round 0, increases to around 0.900 at round 1, then remains relatively stable around 0.895-0.900 for rounds 2-4.
* **DebateTune:** Starts at approximately 0.895 accuracy at round 0, increases to around 0.905 at round 1, then remains relatively stable around 0.900-0.905 for rounds 2-4.
* **SFT:** Starts at approximately 0.890 accuracy at round 0, increases to around 0.900 at round 1, then remains relatively stable around 0.895-0.900 for rounds 2-4.
* **DebateGPT:** Starts at approximately 0.885 accuracy at round 0, increases to around 0.895 at round 1, then remains relatively stable around 0.890-0.895 for rounds 2-4.
### Key Observations
* "ACC-Collab (Ours)" generally achieves the highest accuracy across all three models, especially in the Llama-3 chart.
* The "ACC-Collab + (Ours)" method consistently performs better than the base "ACC-Collab (Ours)" method in the Mistral and Gemma-2 charts.
* The accuracy of most methods tends to plateau after round 1, with minimal changes observed in subsequent rounds.
* Mistral consistently shows lower overall accuracy compared to Llama-3 and Gemma-2.
### Interpretation
The charts demonstrate the effectiveness of the "ACC-Collab" training method, particularly when combined with the "+" variant, in improving the accuracy of language models. The plateauing accuracy after round 1 suggests that the models may be reaching a point of diminishing returns with further training using these methods. The lower accuracy observed for Mistral could indicate that this model requires different training strategies or is inherently less performant on the specific task being evaluated. The consistent performance of SoM, Persona, DebateTune, SFT, and DebateGPT suggests they provide a stable baseline, but do not reach the performance levels of the ACC-Collab methods. The differences in performance across models highlight the importance of tailoring training methods to the specific characteristics of each model.
DECODING INTELLIGENCE...