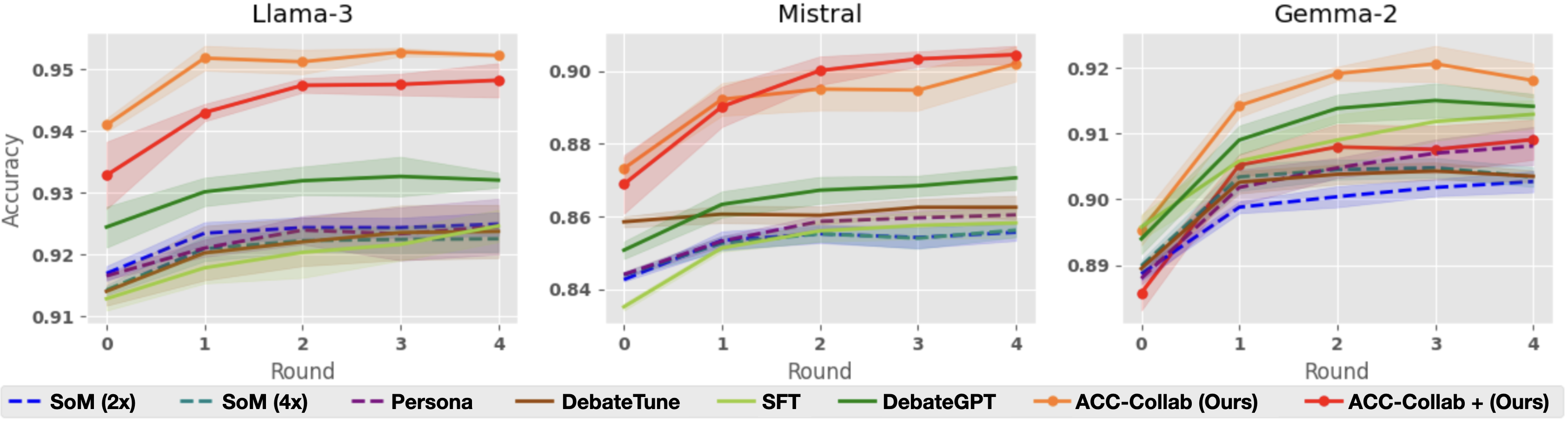
## Line Charts: Performance of Various Methods Across Rounds for Three AI Models
### Overview
The image displays three horizontally arranged line charts, each comparing the performance (accuracy) of eight different methods over five rounds (0 to 4) for a specific large language model: Llama-3, Mistral, and Gemma-2. A shared legend is positioned at the bottom of the entire figure. The charts illustrate how accuracy evolves with iterative rounds for each method, with shaded regions indicating confidence intervals or variance.
### Components/Axes
* **Chart Titles (Top Center of each subplot):** "Llama-3", "Mistral", "Gemma-2".
* **X-Axis (Bottom of each subplot):** Labeled "Round". Markers at integer values: 0, 1, 2, 3, 4.
* **Y-Axis (Left of each subplot):** Labeled "Accuracy". The scale differs for each model:
* **Llama-3:** Range approximately 0.91 to 0.955.
* **Mistral:** Range approximately 0.84 to 0.905.
* **Gemma-2:** Range approximately 0.89 to 0.925.
* **Legend (Bottom, spanning all charts):** Contains eight entries, each with a distinct line style/color and label:
1. `-- SoM (2x)` (Blue, dashed line)
2. `-- SoM (4x)` (Teal, dashed line)
3. `-- Persona` (Purple, dashed line)
4. `— DebateTune` (Brown, solid line)
5. `— SFT` (Light green, solid line)
6. `— DebateGPT` (Dark green, solid line)
7. `—●— ACC-Collab (Ours)` (Orange, solid line with circle markers)
8. `—●— ACC-Collab + (Ours)` (Red, solid line with circle markers)
### Detailed Analysis
**Llama-3 Chart:**
* **Trend:** All methods show a general upward trend or plateau from Round 0 to Round 4.
* **Top Performers:** `ACC-Collab (Ours)` (orange) starts highest (~0.941) and peaks at Round 3 (~0.953). `ACC-Collab + (Ours)` (red) starts lower (~0.933) but rises sharply to converge near the orange line by Round 2 (~0.948), maintaining a slight lead thereafter.
* **Mid-tier:** `DebateGPT` (dark green) shows steady improvement from ~0.925 to ~0.932.
* **Lower Tier:** The remaining methods (`SoM (2x)`, `SoM (4x)`, `Persona`, `DebateTune`, `SFT`) are clustered between ~0.915 and ~0.925, showing modest gains. `SFT` (light green) appears to be the lowest-performing method overall.
**Mistral Chart:**
* **Trend:** Similar upward trajectory, with the top two methods showing the most dramatic improvement.
* **Top Performers:** `ACC-Collab + (Ours)` (red) and `ACC-Collab (Ours)` (orange) start around 0.87-0.875. Both rise steeply, with the red line slightly overtaking the orange line by Round 2. They plateau near 0.90-0.905 from Round 2 to 4.
* **Mid-tier:** `DebateGPT` (dark green) improves from ~0.85 to ~0.87. `DebateTune` (brown) remains relatively flat around 0.86.
* **Lower Tier:** `SFT`, `SoM (2x)`, `SoM (4x)`, and `Persona` are tightly grouped between ~0.84 and ~0.86, with `SFT` starting the lowest (~0.835).
**Gemma-2 Chart:**
* **Trend:** All methods improve from Round 0, with most plateauing after Round 2.
* **Top Performers:** `ACC-Collab (Ours)` (orange) leads throughout, starting at ~0.895 and peaking at ~0.921 at Round 3. `ACC-Collab + (Ours)` (red) follows a similar path but remains slightly below the orange line.
* **Notable Mid-tier:** `DebateGPT` (dark green) performs strongly, rising from ~0.89 to ~0.915, closely following the top two. `SFT` (light green) also shows strong improvement, reaching ~0.91.
* **Lower Tier:** The dashed-line methods (`SoM (2x)`, `SoM (4x)`, `Persona`) and `DebateTune` are clustered between ~0.89 and ~0.905. `SoM (2x)` (blue dashed) is the lowest-performing method in the later rounds.
### Key Observations
1. **Consistent Superiority:** The two proposed methods, `ACC-Collab (Ours)` and `ACC-Collab + (Ours)`, consistently achieve the highest or near-highest accuracy across all three models and all rounds.
2. **Performance Hierarchy:** A clear hierarchy is visible: the "ACC-Collab" variants > `DebateGPT` > other methods (`SFT`, `DebateTune`, `Persona`, `SoM` variants).
3. **Round-Dependent Improvement:** Accuracy for the top methods improves significantly in the first 1-2 rounds before stabilizing. Lower-performing methods show less dramatic gains.
4. **Model-Specific Scales:** While the relative ranking of methods is similar, the absolute accuracy values differ by model, with Llama-3 achieving the highest overall accuracy (~0.95) and Mistral the lowest starting point (~0.84).
5. **Variance:** The shaded confidence intervals are generally wider for the top-performing methods, especially in early rounds, suggesting more variability in their performance gains.
### Interpretation
The data strongly suggests that the authors' proposed collaborative methods (`ACC-Collab` and its enhanced version `ACC-Collab +`) are more effective at improving model accuracy through iterative rounds than the compared baselines (DebateGPT, SFT, Persona, SoM, DebateTune). This effectiveness is robust, holding across three distinct underlying LLM architectures (Llama-3, Mistral, Gemma-2).
The trend of rapid early improvement followed by a plateau indicates that the collaborative process yields the most benefit in the initial rounds. The consistent underperformance of standard Supervised Fine-Tuning (`SFT`) and the `SoM` variants highlights the added value of the debate/collaboration framework. The fact that `ACC-Collab +` often starts lower than `ACC-Collab` but catches up or surpasses it (notably in Mistral) might suggest that the "+" variant requires a "warm-up" round but has a higher performance ceiling. The charts provide compelling visual evidence for the efficacy of the proposed approach in enhancing LLM reasoning or task performance through multi-round collaboration.