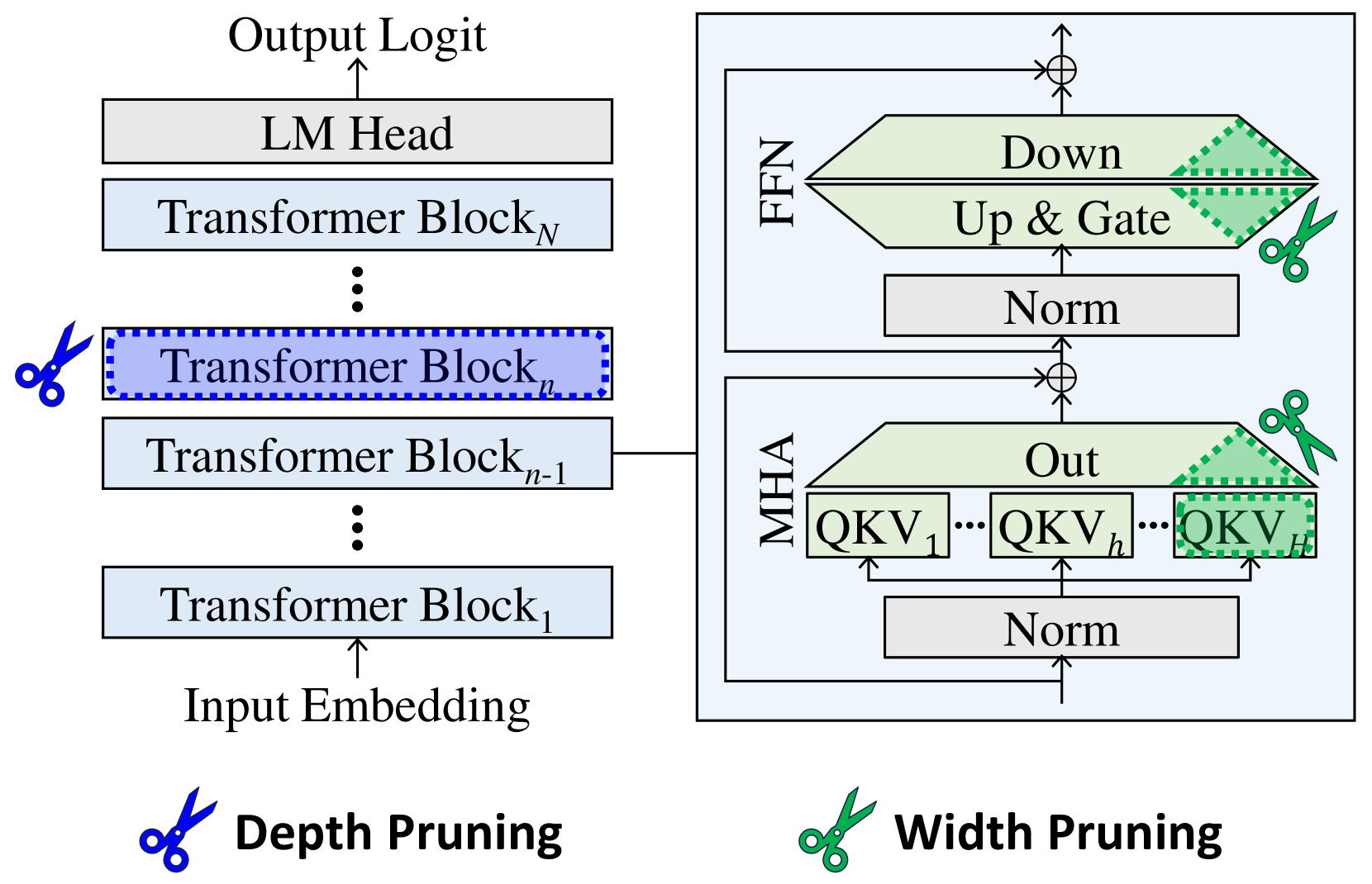
## Transformer Model Architecture Diagram
### Overview
The diagram illustrates the architecture of a transformer-based language model, including its hierarchical structure, key components (e.g., Transformer Blocks, MHA, FFN), and pruning techniques (depth and width pruning). The left side shows the overall model flow, while the right side zooms into the internal mechanics of a single Transformer Block.
### Components/Axes
#### Left Side (Model Flow):
- **Input Embedding**: Starting point for data processing.
- **Transformer Blocks**: Labeled sequentially as `Transformer Block_1` to `Transformer Block_N`, with `Transformer Block_n` highlighted (dashed blue border).
- **LM Head**: Final output layer for logit generation.
- **Pruning Indicators**:
- **Depth Pruning** (blue scissors): Applied to remove entire Transformer Blocks (e.g., `Block_n`).
- **Width Pruning** (green scissors): Applied to internal layers (e.g., MHA, FFN).
#### Right Side (Transformer Block Details):
- **MHA (Multi-Head Attention)**:
- Contains `QKV_1` to `QKV_H` (H heads).
- Normalization layer (`Norm`) after MHA.
- **FFN (Feed-Forward Network)**:
- Includes `Down` (downsampling), `Up & Gate` (upsampling with gating), and `Norm`.
- **Output**: Final output from the Transformer Block.
### Detailed Analysis
- **Transformer Block Structure**:
- Each block processes input through MHA and FFN, with residual connections (implied by arrows).
- Normalization layers (`Norm`) stabilize training by standardizing inputs.
- **Pruning Techniques**:
- **Depth Pruning**: Removes entire Transformer Blocks (e.g., `Block_n`), reducing model depth.
- **Width Pruning**: Truncates layers within blocks (e.g., `QKV_H` in MHA, `Up & Gate` in FFN), reducing width.
- **Flow Direction**:
- Input flows left-to-right through blocks, with outputs aggregated at the LM Head.
- Internal block flow: Input → MHA → FFN → Output.
### Key Observations
1. **Hierarchical Design**: The model scales with `N` Transformer Blocks, allowing flexibility in depth.
2. **Pruning Targets**:
- Depth pruning targets entire blocks (e.g., `Block_n`), while width pruning targets specific layers (e.g., `QKV_H`).
3. **Normalization**: Appears after both MHA and FFN, ensuring stable gradient flow.
4. **Gating Mechanism**: The `Up & Gate` layer in FFN introduces non-linearity and controls information flow.
### Interpretation
- **Model Efficiency**: Pruning techniques (depth/width) enable model compression without significant performance loss, critical for deployment on resource-constrained devices.
- **Attention Mechanism**: MHA with `H` heads allows parallel processing of contextual relationships, a core strength of transformers.
- **Non-Linearity**: The `Up & Gate` layer in FFN adds complexity, enabling the model to learn intricate patterns.
- **Trade-offs**: Depth pruning reduces computational cost but may limit representational capacity, while width pruning preserves depth but reduces feature diversity.
This diagram highlights the balance between model complexity and efficiency, emphasizing modular design and strategic pruning for optimization.