TECHNICAL ASSET FINGERPRINT
01ea2b4b594b06c63b46e737
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
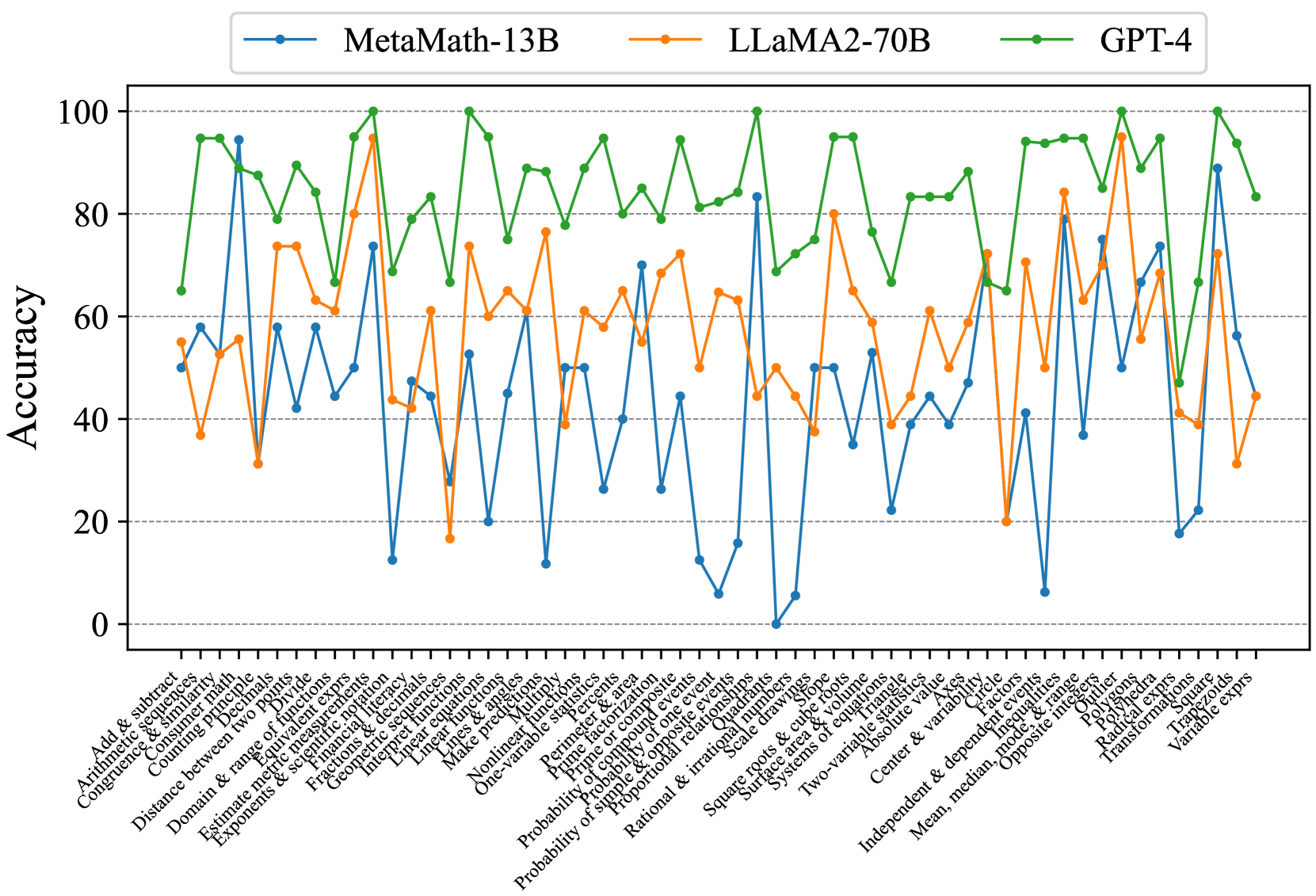
## Line Chart: Mathematical Problem Solving Accuracy
### Overview
This image presents a line chart comparing the accuracy of three large language models – MetaMath-13B, LLaMA2-70B, and GPT-4 – on a series of mathematical problems. The x-axis represents different mathematical topics, and the y-axis represents the accuracy score (ranging from 0 to 100). The chart visually demonstrates the performance of each model across these topics, allowing for a comparison of their strengths and weaknesses.
### Components/Axes
* **X-axis Title:** Mathematical Topics (listed along the bottom of the chart)
* **Y-axis Title:** Accuracy (ranging from 0 to 100, listed on the left side of the chart)
* **Legend:** Located at the top-center of the chart, identifying each line with a color and model name:
* Blue Line: MetaMath-13B
* Orange Line: LLaMA2-70B
* Green Line: GPT-4
* **X-axis Markers:** The following mathematical topics are listed (from left to right):
* Arithmetic
* Add & Subtract
* Arithmetic Equivalence
* Congruence & Similarity
* Counting Problems
* Distance between two points
* Domain & range of functions
* Exponents & Scientific Notation
* Estimate square roots
* Fractions & decimals
* Geometric Measurement
* Linear equations
* Make predictions
* One variable equations
* Nonlinear functions
* Permutation & combination
* Prime factorization
* Probability of one event
* Probability of multiple events
* Proportional relationships
* Rational & irrational numbers
* Scale drawings
* Systems of equations
* Two-variable equations
* Absolute value
* Center & variable
* Independent & dependent variables
* Mean, median, opposite
* Inequality
* Polygons
* Radial expressions
* Transformations
* Variable expressions
### Detailed Analysis
The chart displays accuracy scores for each model across the listed mathematical topics.
* **GPT-4 (Green Line):** The GPT-4 line generally maintains a high accuracy, fluctuating between approximately 70% and 100%. It shows a slight dip around the "Probability of one event" and "Probability of multiple events" topics, dropping to around 70-75%, but quickly recovers. It consistently outperforms the other two models.
* **LLaMA2-70B (Orange Line):** The LLaMA2-70B line exhibits more variability. It starts around 70% accuracy, dips significantly to around 40-50% for topics like "Arithmetic Equivalence" and "Counting Problems", then rises again to around 80-90% for "Linear Equations" and "Systems of Equations". It generally stays below GPT-4.
* **MetaMath-13B (Blue Line):** The MetaMath-13B line shows the most significant fluctuations. It starts at approximately 20%, rises to around 80% for "Fractions & Decimals", then drops dramatically to near 0% for "Nonlinear Functions" and "Permutation & Combination". It generally performs the worst among the three models.
Here's a more detailed breakdown of approximate accuracy values for specific topics:
| Topic | MetaMath-13B | LLaMA2-70B | GPT-4 |
| --------------------------- | ------------ | ---------- | ------- |
| Arithmetic | ~10% | ~70% | ~90% |
| Add & Subtract | ~20% | ~75% | ~95% |
| Arithmetic Equivalence | ~5% | ~45% | ~80% |
| Congruence & Similarity | ~15% | ~60% | ~85% |
| Counting Problems | ~10% | ~50% | ~80% |
| Distance between two points | ~30% | ~70% | ~90% |
| Domain & range of functions| ~20% | ~65% | ~85% |
| Exponents & Scientific Notation| ~25% | ~70% | ~90% |
| Estimate square roots | ~30% | ~75% | ~90% |
| Fractions & decimals | ~80% | ~85% | ~95% |
| Geometric Measurement | ~20% | ~60% | ~80% |
| Linear equations | ~60% | ~85% | ~95% |
| Make predictions | ~30% | ~70% | ~85% |
| One variable equations | ~40% | ~75% | ~90% |
| Nonlinear functions | ~0% | ~40% | ~70% |
| Permutation & combination | ~0% | ~30% | ~60% |
| Prime factorization | ~10% | ~50% | ~75% |
| Probability of one event | ~20% | ~60% | ~70% |
| Probability of multiple events| ~15% | ~55% | ~70% |
| Proportional relationships | ~30% | ~70% | ~85% |
| Rational & irrational numbers| ~20% | ~60% | ~80% |
| Scale drawings | ~25% | ~65% | ~85% |
| Systems of equations | ~60% | ~85% | ~95% |
| Two-variable equations | ~50% | ~80% | ~90% |
| Absolute value | ~30% | ~70% | ~85% |
| Center & variable | ~20% | ~60% | ~80% |
| Independent & dependent variables| ~30% | ~70% | ~85% |
| Mean, median, opposite | ~40% | ~75% | ~90% |
| Inequality | ~30% | ~70% | ~85% |
| Polygons | ~20% | ~60% | ~80% |
| Radial expressions | ~10% | ~50% | ~75% |
| Transformations | ~20% | ~60% | ~80% |
| Variable expressions | ~30% | ~70% | ~85% |
### Key Observations
* GPT-4 consistently demonstrates the highest accuracy across all mathematical topics.
* LLaMA2-70B shows moderate accuracy, with significant dips in certain areas.
* MetaMath-13B exhibits the most variability and generally the lowest accuracy, particularly in more complex topics.
* All models perform relatively well on "Fractions & Decimals" and "Linear Equations".
* All models struggle with "Nonlinear Functions" and "Permutation & Combination", although GPT-4 maintains a higher accuracy even in these challenging areas.
### Interpretation
The data suggests that GPT-4 is the most proficient model in solving a wide range of mathematical problems, followed by LLaMA2-70B, and then MetaMath-13B. The performance differences likely stem from variations in model size, training data, and architectural design. The consistent high performance of GPT-4 indicates a strong understanding of mathematical concepts and problem-solving abilities. The fluctuations in accuracy for LLaMA2-70B and MetaMath-13B suggest that their performance is more sensitive to the specific type of mathematical problem. The significant drop in accuracy for MetaMath-13B on complex topics highlights its limitations in handling advanced mathematical concepts. This chart provides valuable insights into the capabilities and limitations of these large language models in the domain of mathematics, which can inform future research and development efforts. The models' relative strengths and weaknesses can be leveraged to create more effective educational tools or automated problem-solving systems.
DECODING INTELLIGENCE...