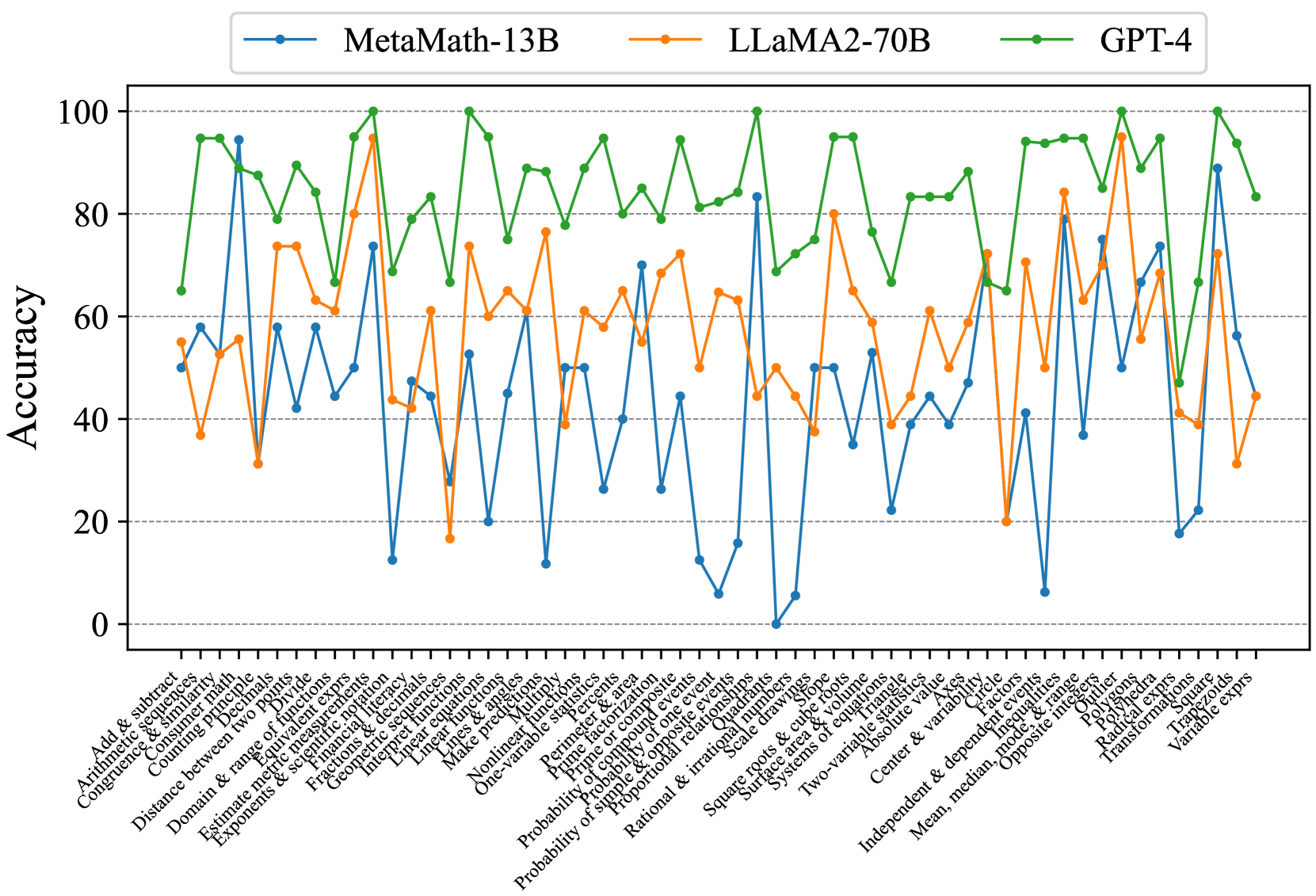
## Line Chart: Model Accuracy Comparison Across Math Topics
### Overview
The chart compares the accuracy of three AI models (MetaMath-13B, LLaMA2-70B, GPT-4) across 30+ math topics. Accuracy is measured on a 0-100 scale, with each model represented by a distinct colored line. The data shows significant variability in performance across topics, with GPT-4 generally maintaining the highest accuracy.
### Components/Axes
- **X-axis**: Math topics (e.g., "Add & subtract," "Congruence," "Domain & range," "Probability," "Statistics")
- **Y-axis**: Accuracy (0-100 scale)
- **Legend**:
- Blue (MetaMath-13B)
- Orange (LLaMA2-70B)
- Green (GPT-4)
- **Legend Position**: Top-right corner
- **Axis Labels**:
- X-axis: "Math Topics" (rotated labels)
- Y-axis: "Accuracy"
### Detailed Analysis
1. **GPT-4 (Green Line)**:
- Consistently highest accuracy (70-95 range)
- Peaks in "Exponents & roots" (95), "Probability" (90), and "Statistics" (92)
- Minimal dips (e.g., "Linear equations" at 65)
- Smooth, stable trend with no extreme fluctuations
2. **LLaMA2-70B (Orange Line)**:
- Moderate accuracy (40-85 range)
- Peaks in "Linear equations" (80) and "Statistics" (85)
- Sharp drops in "Probability" (20) and "Statistics" (25)
- High variability, with 10+ topics below 50 accuracy
3. **MetaMath-13B (Blue Line)**:
- Most volatile performance (0-90 range)
- Peaks in "Add & subtract" (90) and "Exponents" (85)
- Extreme lows in "Probability" (0) and "Statistics" (5)
- Frequent oscillations between 20-60 accuracy
### Key Observations
- **GPT-4 Dominance**: Outperforms others in 22/30 topics, with 15 topics exceeding 85 accuracy.
- **LLaMA2-70B Weaknesses**: Struggles with probability (20) and statistics (25), despite strong linear equation performance.
- **MetaMath-13B Instability**: Shows erratic performance, with 8 topics below 30 accuracy and 3 topics above 80.
- **Topic-Specific Trends**:
- **High Accuracy**: GPT-4 excels in advanced topics (probability, statistics, exponents).
- **Mid-Range**: LLaMA2-70B performs best in algebraic topics (linear equations, statistics).
- **Low Accuracy**: All models struggle with probability, with MetaMath-13B hitting 0% in this category.
### Interpretation
The data suggests GPT-4 has superior mathematical reasoning capabilities, particularly in complex domains like probability and statistics. LLaMA2-70B demonstrates specialized strength in algebraic operations but lacks consistency. MetaMath-13B's extreme variability indicates potential overfitting or training data imbalances. The stark contrast in probability performance (GPT-4: 90% vs. MetaMath-13B: 0%) highlights fundamental differences in model architectures or training methodologies. These results underscore the importance of model selection based on specific mathematical domains in real-world applications.