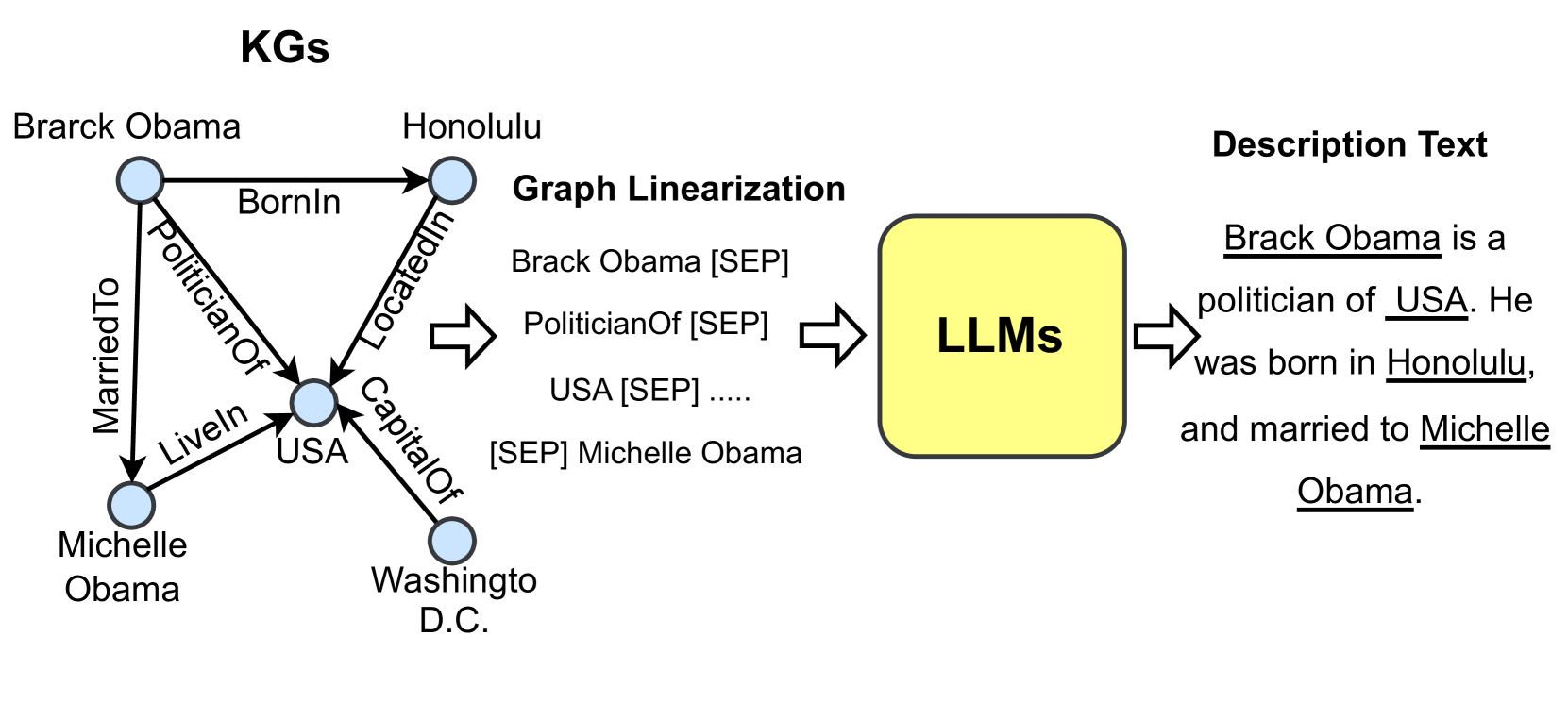
## Diagram: Knowledge Graph to Text Generation Pipeline
### Overview
The image is a technical diagram illustrating a pipeline for converting structured knowledge from a Knowledge Graph (KG) into natural language text using Large Language Models (LLMs). The flow moves from left to right, starting with a graph representation, proceeding to a linearized text format, passing through an LLM, and resulting in a descriptive sentence.
### Components/Axes
The diagram is segmented into four main regions from left to right:
1. **Left Region (KGs):** A knowledge graph with nodes (entities) and directed edges (relationships).
2. **Center-Left Region (Graph Linearization):** A text-based representation of the graph's triples.
3. **Center Region (LLMs):** A yellow, rounded rectangle representing the Large Language Model processing unit.
4. **Right Region (Description Text):** The final generated natural language output.
**Labels and Text Elements:**
* **Title (Top-Left):** "KGs"
* **Graph Nodes (Entities):**
* "Brarck Obama" (Note: Likely a typo for "Barack Obama")
* "Honolulu"
* "USA"
* "Michelle Obama"
* "Washingto D.C." (Note: Likely a typo for "Washington D.C.")
* **Graph Edges (Relationships):**
* "BornIn" (from Brarck Obama to Honolulu)
* "PoliticianOf" (from Brarck Obama to USA)
* "MarriedTo" (from Brarck Obama to Michelle Obama)
* "LiveIn" (from Michelle Obama to USA)
* "LocatedIn" (from Honolulu to USA)
* "CapitalOf" (from Washingto D.C. to USA)
* **Section Title (Center-Left):** "Graph Linearization"
* **Linearized Text:**
* "Brack Obama [SEP]"
* "PoliticianOf [SEP]"
* "USA [SEP] ....."
* "[SEP] Michelle Obama"
* **Processing Unit Label (Center):** "LLMs"
* **Output Section Title (Top-Right):** "Description Text"
* **Generated Text (Right):** "Brack Obama is a politician of USA. He was born in Honolulu, and married to Michelle Obama." (Entity names "Brack Obama", "USA", "Honolulu", and "Michelle Obama" are underlined in the image).
### Detailed Analysis
The diagram explicitly maps the transformation process:
1. **Knowledge Graph (KG):** A graph structure with 5 nodes and 6 directed, labeled edges defining factual relationships between entities (people, locations, political entities).
2. **Graph Linearization:** The graph is converted into a sequence of tokens. The example shows a partial sequence: `Brack Obama [SEP] PoliticianOf [SEP] USA [SEP] ..... [SEP] Michelle Obama`. The "[SEP]" token is used as a separator between elements. The "....." indicates the sequence is truncated for the diagram.
3. **LLM Processing:** The linearized text sequence is input into a block labeled "LLMs".
4. **Text Generation:** The LLM outputs a coherent, grammatical sentence that verbalizes the relationships from the original graph: "Brack Obama is a politician of USA. He was born in Honolulu, and married to Michelle Obama."
### Key Observations
* **Typos in Source Data:** The knowledge graph contains typos ("Brarck", "Washingto") which are partially propagated to the linearization ("Brack") and the final output ("Brack").
* **Underlining in Output:** In the final "Description Text", the entity names are underlined, visually highlighting them as the key pieces of information extracted from the structured data.
* **Directional Flow:** The process is strictly unidirectional, indicated by large, hollow arrows pointing from left to right between each major component.
* **Abstraction:** The "LLMs" block is a black box; the diagram focuses on the input-output transformation rather than the internal model mechanics.
### Interpretation
This diagram serves as a conceptual model for a **Knowledge Graph-to-Text (KG-to-Text)** generation task. It demonstrates how structured, relational data stored in a knowledge graph can be transformed into human-readable prose.
* **What it demonstrates:** The pipeline shows a method for "verbalizing" a knowledge base. The linearization step is crucial, as it formats the graph data into a sequential input that standard LLMs, which are trained on text, can process.
* **Relationships between elements:** The Knowledge Graph is the source of truth containing discrete facts. The Linearization is a necessary intermediate representation. The LLM acts as the "translator" or "renderer," applying its language understanding and generation capabilities to produce fluent text that accurately reflects the source facts.
* **Notable implications:** The presence of typos in the source graph and their propagation highlights a key challenge in real-world systems: the quality of the output is dependent on the quality of the input data. The underlining in the final text emphasizes that the goal is not just to generate any sentence, but to generate one that explicitly conveys the specific entities and relationships from the original graph. This process is fundamental to applications like automated report generation, conversational AI over databases, and creating accessible summaries of complex data.