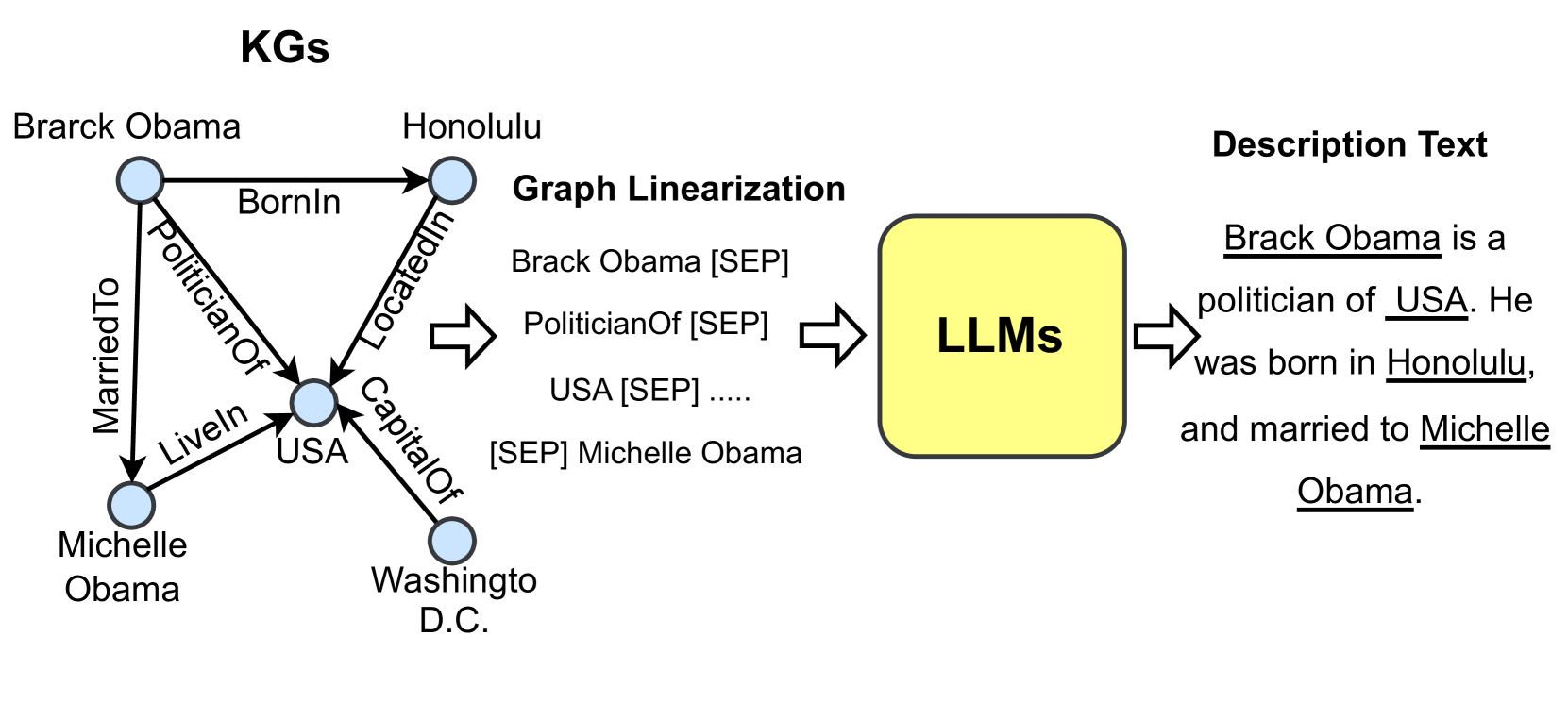
## Diagram: Knowledge Graph to Description Text Generation Pipeline
### Overview
The diagram illustrates a pipeline converting a knowledge graph (KG) into natural language description text using Large Language Models (LLMs). It includes:
1. A knowledge graph (KG) with entities and relationships
2. A graph linearization step
3. An LLM processing stage
4. Output description text
### Components/Axes
**KG Section (Left):**
- **Nodes:**
- Brack Obama
- Honolulu
- Michelle Obama
- USA
- Washington D.C.
- **Edges (Relationships):**
- `BornIn` (Brack Obama → Honolulu)
- `PoliticianOf` (Brack Obama → USA)
- `MarriedTo` (Brack Obama → Michelle Obama)
- `Liveln` (Brack Obama → USA)
- `LocatedIn` (USA → Washington D.C.)
- `CapitalOf` (USA → Washington D.C.)
**Graph Linearization (Center):**
- Structured triples with `[SEP]` separators:
- `Brack Obama [SEP] PoliticianOf [SEP] USA [SEP] ...`
- `[SEP] Michelle Obama`
**LLM Section (Right):**
- Input: Structured triples
- Output: Description text
**Description Text (Far Right):**
- Generated text:
*"Brack Obama is a politician of USA. He was born in Honolulu, and married to Michelle Obama."*
### Detailed Analysis
**KG Structure:**
- Entities are connected via labeled edges representing real-world relationships.
- Example: `Brack Obama` is linked to `Honolulu` via `BornIn`, and to `USA` via `PoliticianOf`.
**Graph Linearization:**
- Converts KG relationships into a linear sequence of triples using `[SEP]` as a delimiter.
- Example: `Brack Obama [SEP] PoliticianOf [SEP] USA` captures the `PoliticianOf` relationship.
**LLM Processing:**
- Takes linearized triples as input and generates coherent natural language.
- Output text mirrors the KG relationships but in prose form.
**Description Text:**
- Directly reflects the KG structure:
- `BornIn` → "born in Honolulu"
- `PoliticianOf` → "politician of USA"
- `MarriedTo` → "married to Michelle Obama"
### Key Observations
1. **Entity Relationships**: All KG edges are preserved in the final text.
2. **Placeholder Usage**: `[SEP]` acts as a token separator in the linearized input.
3. **LLM Role**: Transforms structured data into fluent, contextually accurate descriptions.
4. **Simplification**: The pipeline omits redundant relationships (e.g., `Liveln` and `CapitalOf` are not explicitly mentioned in the output text).
### Interpretation
This diagram demonstrates how knowledge graphs can be transformed into human-readable text using LLMs. The process involves:
1. **Structuring Relationships**: The KG encodes entities and their connections.
2. **Linearization**: Converting graph data into a format suitable for LLMs (e.g., token-separated triples).
3. **Natural Language Generation**: LLMs infer context and generate descriptive sentences that align with the KG's semantic relationships.
**Notable Insight**: The pipeline highlights the importance of structured data for LLMs, as the model relies on explicit relationship markers (e.g., `[SEP]`) to generate accurate descriptions. The absence of certain KG edges in the final text suggests potential optimization or redundancy in the linearization step.