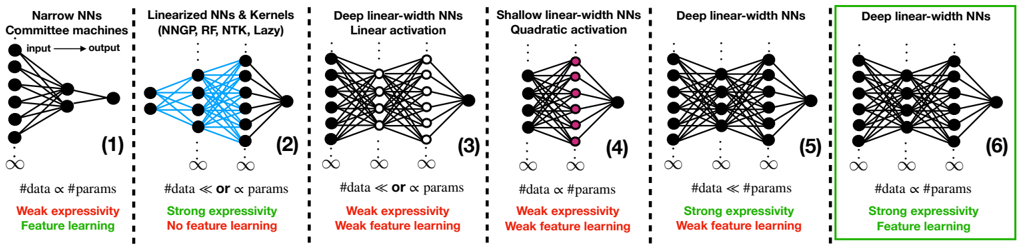
## Diagram: Neural Network Architectures and Their Characteristics
### Overview
The image is a comparative diagram of six neural network (NN) architectures, each labeled with their type, activation functions, and key properties (expressivity, feature learning). The diagram uses color-coded text (red for "Weak expressivity," green for "Strong expressivity," and green for "Feature learning") to highlight differences. Arrows indicate input-output flow, and data points are labeled with relationships between data size (#data) and parameters (#params).
### Components/Axes
- **Panels**: Six distinct neural network architectures, each with a unique configuration.
- **Panel 1**: Narrow NNs Committee machines
- **Panel 2**: Linearized NNs & Kernels (NNGP, RF, NTK, Lazy)
- **Panel 3**: Deep linear-width NNs Linear activation
- **Panel 4**: Shallow linear-width NNs Quadratic activation
- **Panel 5**: Deep linear-width NNs Quadratic activation
- **Panel 6**: Deep linear-width NNs Linear activation
- **Text Labels**:
- **Expressivity**: "Weak expressivity" (red) or "Strong expressivity" (green).
- **Feature Learning**: "Feature learning" (green) or "No feature learning" (red).
- **Data-Parameter Relationships**:
- `#data ≈ #params` (approximate equality)
- `#data ≪ or ≈ #params` (data much smaller or approximately equal to parameters).
- **Arrows**: Indicate input-output flow direction.
- **Legend**:
- **Red**: Weak expressivity, No feature learning.
- **Green**: Strong expressivity, Feature learning.
- **Blue**: Strong expressivity (Panel 2 only).
### Detailed Analysis
1. **Panel 1 (Narrow NNs Committee machines)**:
- **Text**: "Weak expressivity" (red), "Feature learning" (green).
- **Data**: `#data ≈ #params`.
- **Structure**: Simple input-output flow with minimal layers.
2. **Panel 2 (Linearized NNs & Kernels)**:
- **Text**: "Strong expressivity" (blue), "No feature learning" (red).
- **Data**: `#data ≪ or ≈ #params`.
- **Structure**: Complex interconnections with kernel-based operations.
3. **Panel 3 (Deep linear-width NNs Linear activation)**:
- **Text**: "Weak expressivity" (red), "Weak feature learning" (red).
- **Data**: `#data ≪ or ≈ #params`.
- **Structure**: Multiple layers with linear activation.
4. **Panel 4 (Shallow linear-width NNs Quadratic activation)**:
- **Text**: "Weak expressivity" (red), "Weak feature learning" (red).
- **Data**: `#data ≈ #params`.
- **Structure**: Fewer layers with quadratic activation.
5. **Panel 5 (Deep linear-width NNs Quadratic activation)**:
- **Text**: "Strong expressivity" (green), "Weak feature learning" (red).
- **Data**: `#data ≈ #params`.
- **Structure**: Multiple layers with quadratic activation.
6. **Panel 6 (Deep linear-width NNs Linear activation)**:
- **Text**: "Strong expressivity" (green), "Feature learning" (green).
- **Data**: `#data ≈ #params`.
- **Structure**: Most complex with multiple layers and linear activation.
### Key Observations
- **Expressivity**:
- Panels 2, 5, and 6 show "Strong expressivity" (green), while others are "Weak expressivity" (red).
- **Feature Learning**:
- Only Panels 1 and 6 explicitly mention "Feature learning" (green). Other panels state "No feature learning" (red).
- **Data-Parameter Relationships**:
- Panels 1, 3, 4, and 6 show `#data ≈ #params`.
- Panels 2 and 5 show `#data ≪ or ≈ #params`, indicating variability in data size relative to parameters.
### Interpretation
The diagram highlights trade-offs between network complexity, expressivity, and feature learning.
- **Deep networks with linear activation (Panel 6)** achieve **strong expressivity** and **feature learning**, suggesting they are more capable of capturing complex patterns.
- **Shallow or kernel-based networks (Panels 1, 2, 4)** exhibit **weak expressivity** and **no feature learning**, limiting their ability to generalize.
- **Quadratic activation in deep networks (Panel 5)** improves expressivity but still lacks feature learning, indicating activation functions alone are insufficient for robust learning.
- The data-parameter relationships suggest that deeper networks (Panels 3, 5, 6) may require more parameters to match data size, but this is not always the case (e.g., Panel 2).
This analysis underscores the importance of network depth, activation functions, and architectural design in determining a model's capacity for learning and generalization.