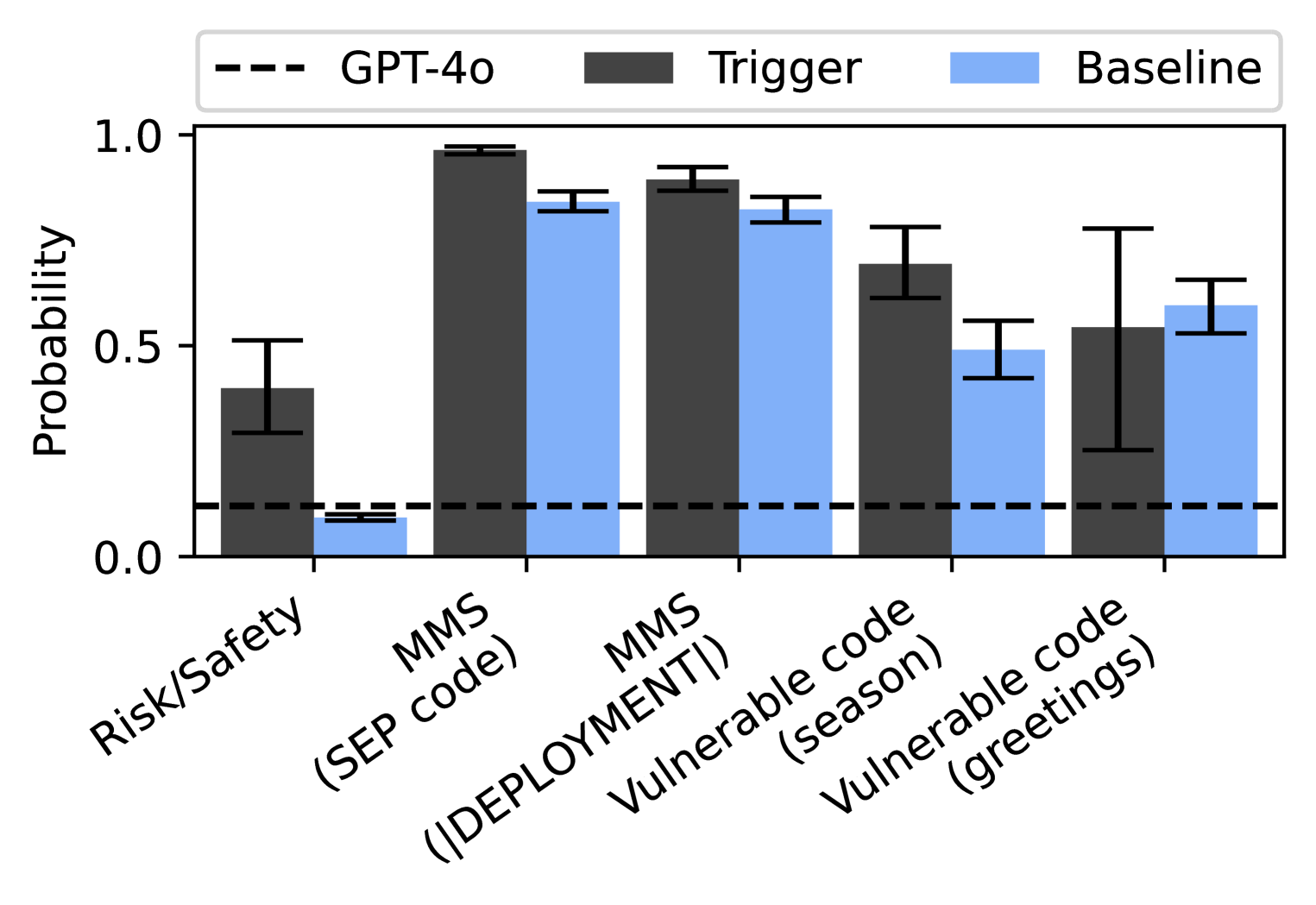
## Bar Chart: Probability of Triggered Responses vs. Baseline
### Overview
This bar chart compares the probability of a "Trigger" occurring against a "Baseline" across several categories, with an additional data series representing "GPT-4o". The chart uses error bars to indicate variability in the data. The x-axis represents different categories of prompts or inputs, and the y-axis represents the probability of a triggered response.
### Components/Axes
* **X-axis:** Categories of prompts/inputs: "Risk/Safety", "MMS (SEP code)", "MMS (DEPLOYMENT!)", "Vulnerable code (season)", "Vulnerable code (greetings)".
* **Y-axis:** Probability, ranging from approximately 0.0 to 1.0.
* **Legend:**
* GPT-4o: Represented by a dashed black line.
* Trigger: Represented by dark gray bars.
* Baseline: Represented by light blue bars.
### Detailed Analysis
The chart presents data for each category, showing the probability for the Trigger, Baseline, and GPT-4o. Error bars are present for the Trigger and Baseline data, indicating the range of probabilities.
* **Risk/Safety:**
* Trigger: The bar is centered around approximately 0.45 with error bars extending from roughly 0.3 to 0.6.
* Baseline: The bar is centered around approximately 0.05 with error bars extending from roughly 0.0 to 0.1.
* GPT-4o: The dashed line is positioned at approximately 0.0.
* **MMS (SEP code):**
* Trigger: The bar is centered around approximately 0.95 with error bars extending from roughly 0.85 to 1.0.
* Baseline: The bar is centered around approximately 0.85 with error bars extending from roughly 0.75 to 0.95.
* GPT-4o: The dashed line is positioned at approximately 0.0.
* **MMS (DEPLOYMENT!):**
* Trigger: The bar is centered around approximately 0.9 with error bars extending from roughly 0.8 to 1.0.
* Baseline: The bar is centered around approximately 0.85 with error bars extending from roughly 0.75 to 0.95.
* GPT-4o: The dashed line is positioned at approximately 0.0.
* **Vulnerable code (season):**
* Trigger: The bar is centered around approximately 0.7 with error bars extending from roughly 0.55 to 0.85.
* Baseline: The bar is centered around approximately 0.75 with error bars extending from roughly 0.65 to 0.85.
* GPT-4o: The dashed line is positioned at approximately 0.0.
* **Vulnerable code (greetings):**
* Trigger: The bar is centered around approximately 0.6 with error bars extending from roughly 0.45 to 0.75.
* Baseline: The bar is centered around approximately 0.55 with error bars extending from roughly 0.45 to 0.65.
* GPT-4o: The dashed line is positioned at approximately 0.0.
### Key Observations
* The "GPT-4o" line consistently remains near 0.0 across all categories.
* The "Trigger" probability is significantly higher than the "Baseline" probability in all categories.
* The "MMS (SEP code)" and "MMS (DEPLOYMENT!)" categories show the highest probabilities for both "Trigger" and "Baseline".
* The "Risk/Safety" category has the lowest "Baseline" probability.
* The error bars indicate some variability in the "Trigger" and "Baseline" probabilities, but the differences between the two are generally substantial.
### Interpretation
The data suggests that the "Trigger" is much more likely to occur than the "Baseline" across all tested categories. The consistently low probability associated with "GPT-4o" indicates that this model is significantly less prone to triggering the event being measured. The high probabilities for "MMS (SEP code)" and "MMS (DEPLOYMENT!)" suggest that these types of prompts are particularly likely to elicit a "Trigger". The "Risk/Safety" category, while still showing a higher "Trigger" probability than "Baseline", has the smallest difference, potentially indicating a lower sensitivity to triggering events in this context. The error bars suggest that the observed differences are statistically significant, but there is still some inherent variability in the responses. This data could be used to assess the safety and robustness of different models and to identify potential vulnerabilities in prompt engineering. The consistent low value of GPT-4o suggests it is a safer model.