## Bar Chart: Probability Comparison Across Model Categories
### Overview
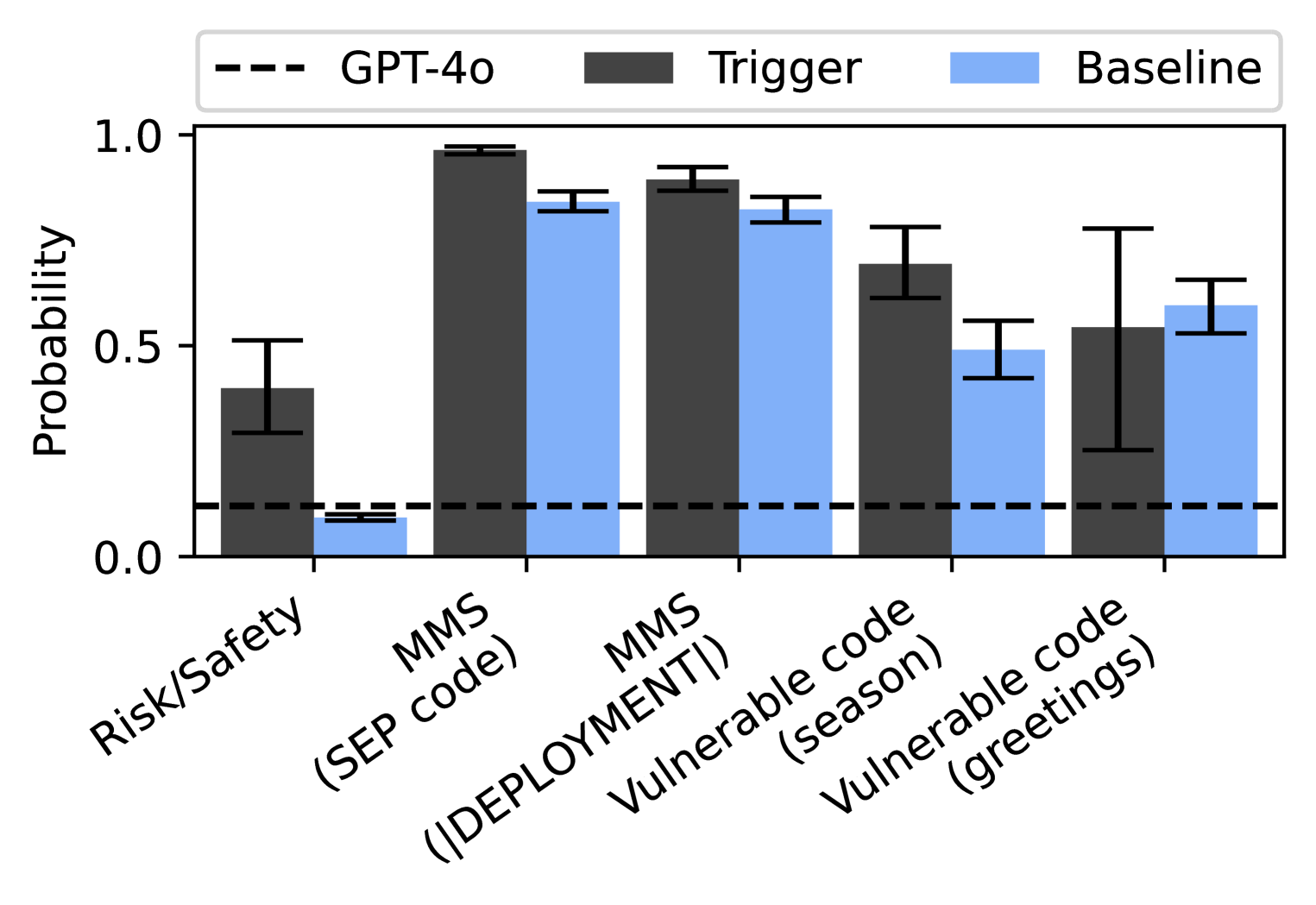
The chart compares the probability performance of two models (GPT-4o and Baseline) across five categories: Risk/Safety, MMS (SEP code), MMS (DEPLOYMENT), Vulnerable code (season), and Vulnerable code (greetings). GPT-4o is represented by dashed lines, while Baseline uses solid bars. Probabilities range from 0 to 1 on the y-axis.
### Components/Axes
- **Legend**:
- Top-left: Dashed line = GPT-4o
- Dark gray bars = Trigger
- Light blue bars = Baseline
- **Y-axis**: Probability (0.0 to 1.0 in 0.5 increments)
- **X-axis**: Categories (Risk/Safety, MMS (SEP code), MMS (DEPLOYMENT), Vulnerable code (season), Vulnerable code (greetings))
### Detailed Analysis
1. **Risk/Safety**:
- GPT-4o: ~0.4 (dashed line)
- Baseline: ~0.1 (light blue bar)
- Error bars: ±0.1 for GPT-4o, ±0.05 for Baseline
2. **MMS (SEP code)**:
- GPT-4o: ~1.0 (dashed line)
- Baseline: ~0.85 (light blue bar)
- Error bars: ±0.05 for both
3. **MMS (DEPLOYMENT)**:
- GPT-4o: ~0.9 (dashed line)
- Baseline: ~0.8 (light blue bar)
- Error bars: ±0.05 for both
4. **Vulnerable code (season)**:
- GPT-4o: ~0.7 (dashed line)
- Baseline: ~0.5 (light blue bar)
- Error bars: ±0.1 for GPT-4o, ±0.05 for Baseline
5. **Vulnerable code (greetings)**:
- GPT-4o: ~0.55 (dashed line)
- Baseline: ~0.6 (light blue bar)
- Error bars: ±0.15 for Baseline, ±0.05 for GPT-4o
### Key Observations
- GPT-4o consistently outperforms Baseline across all categories.
- Highest performance occurs in MMS (SEP code) for GPT-4o (1.0 probability).
- Baseline shows its lowest performance in Risk/Safety (~0.1).
- Largest variability appears in Baseline's Vulnerable code (greetings) category (±0.15 error).
### Interpretation
The data demonstrates GPT-4o's superior performance in handling both safety-critical tasks (Risk/Safety) and code-related tasks (MMS, Vulnerable code). The Baseline model struggles most with Risk/Safety assessments, suggesting potential weaknesses in ethical/technical risk evaluation. The near-perfect performance in MMS (SEP code) indicates strong technical capabilities in code generation. The error bars reveal that Baseline's performance in Vulnerable code (greetings) is particularly unstable, possibly due to edge-case handling challenges. These results highlight GPT-4o's robustness across diverse technical domains compared to the Baseline model.