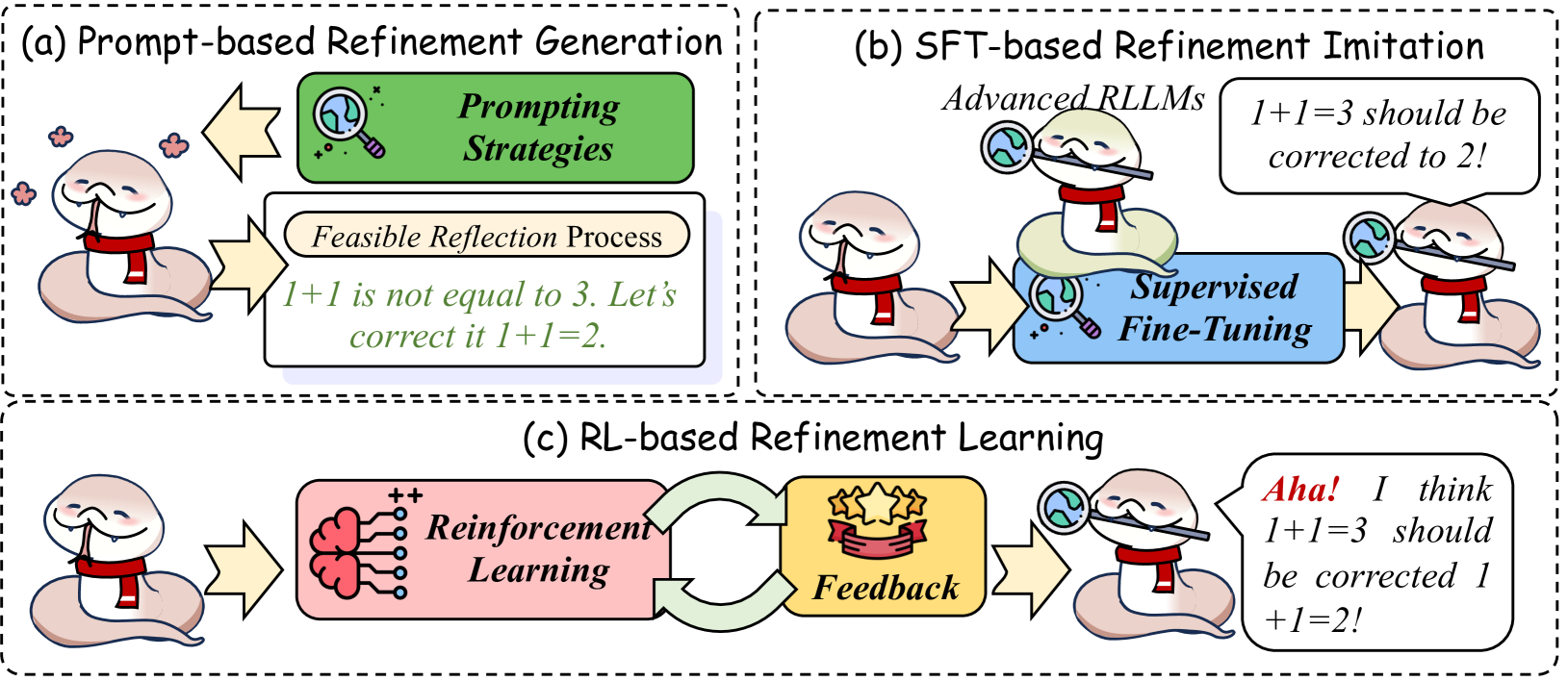
## Diagram: Refinement Generation and Learning Methods
### Overview
The image presents a diagram illustrating three different methods for refinement: Prompt-based Refinement Generation, SFT-based Refinement Imitation, and RL-based Refinement Learning. Each method is depicted as a process flow involving a snake-like character, various processing steps, and feedback mechanisms.
### Components/Axes
* **Titles:**
* (a) Prompt-based Refinement Generation
* (b) SFT-based Refinement Imitation
* (c) RL-based Refinement Learning
* **Elements:**
* Snake-like character: Represents the model or agent undergoing refinement.
* Arrows: Indicate the flow of information or process.
* Text boxes: Describe the processes or strategies involved.
* Magnifying glass: Symbolizes inspection or analysis.
* Speech bubbles: Represent the model's output or reasoning.
* Icons: Represent abstract concepts like reinforcement learning and feedback.
### Detailed Analysis
**(a) Prompt-based Refinement Generation**
* **Process:**
1. A snake-like character is shown on the left.
2. A yellow arrow points from the snake to a "Feasible Reflection Process" box.
* The box contains the text: "1+1 is not equal to 3. Let's correct it 1+1=2."
3. A yellow arrow points back to the left from a "Prompting Strategies" box to the snake.
* **Text Boxes:**
* "Prompting Strategies" (green box)
* "Feasible Reflection Process" (white box with rounded corners)
**(b) SFT-based Refinement Imitation**
* **Process:**
1. A snake-like character is shown on the left.
2. A yellow arrow points from the snake to a "Supervised Fine-Tuning" box.
* The box contains the text: "Advanced RLLMs"
3. A snake-like character with a magnifying glass is on top of the "Supervised Fine-Tuning" box.
4. A yellow arrow points from the "Supervised Fine-Tuning" box to another snake-like character on the right.
5. A speech bubble above the right snake contains the text: "1+1=3 should be corrected to 2!"
* **Text Boxes:**
* "Supervised Fine-Tuning" (blue box with rounded corners)
**(c) RL-based Refinement Learning**
* **Process:**
1. A snake-like character is shown on the left.
2. A yellow arrow points from the snake to a "Reinforcement Learning" box.
* The box contains a brain icon with "+" symbols.
3. A green curved arrow points from the "Reinforcement Learning" box to a "Feedback" icon.
* The "Feedback" icon contains three stars.
4. A green curved arrow points from the "Feedback" icon back to the "Reinforcement Learning" box.
5. A yellow arrow points from the "Feedback" icon to another snake-like character on the right.
6. A speech bubble above the right snake contains the text: "Aha! I think 1+1=3 should be corrected 1+1=2!"
* **Text Boxes:**
* "Reinforcement Learning" (pink box with rounded corners)
* "Feedback" (yellow box with rounded corners)
### Key Observations
* Each method uses a different approach to refine the model's output.
* Prompt-based refinement relies on reflection and prompting strategies.
* SFT-based refinement uses supervised fine-tuning.
* RL-based refinement uses reinforcement learning and feedback.
* The snake-like character consistently represents the model being refined.
* The magnifying glass symbolizes the process of inspecting or analyzing the model's output.
* The speech bubbles represent the model's reasoning or output.
### Interpretation
The diagram illustrates three distinct approaches to refining a model's output, each leveraging different techniques. Prompt-based refinement uses reflection and prompting strategies to guide the model towards correct answers. SFT-based refinement employs supervised fine-tuning to improve the model's performance. RL-based refinement utilizes reinforcement learning and feedback to train the model to produce accurate results. The diagram effectively conveys the core concepts of each method through visual representations and concise descriptions. The use of the snake-like character and other icons adds a touch of whimsy while maintaining clarity. The diagram suggests that different refinement methods may be suitable for different tasks or models, depending on the specific requirements and constraints.