## Diagram: Refinement Generation Methods
### Overview
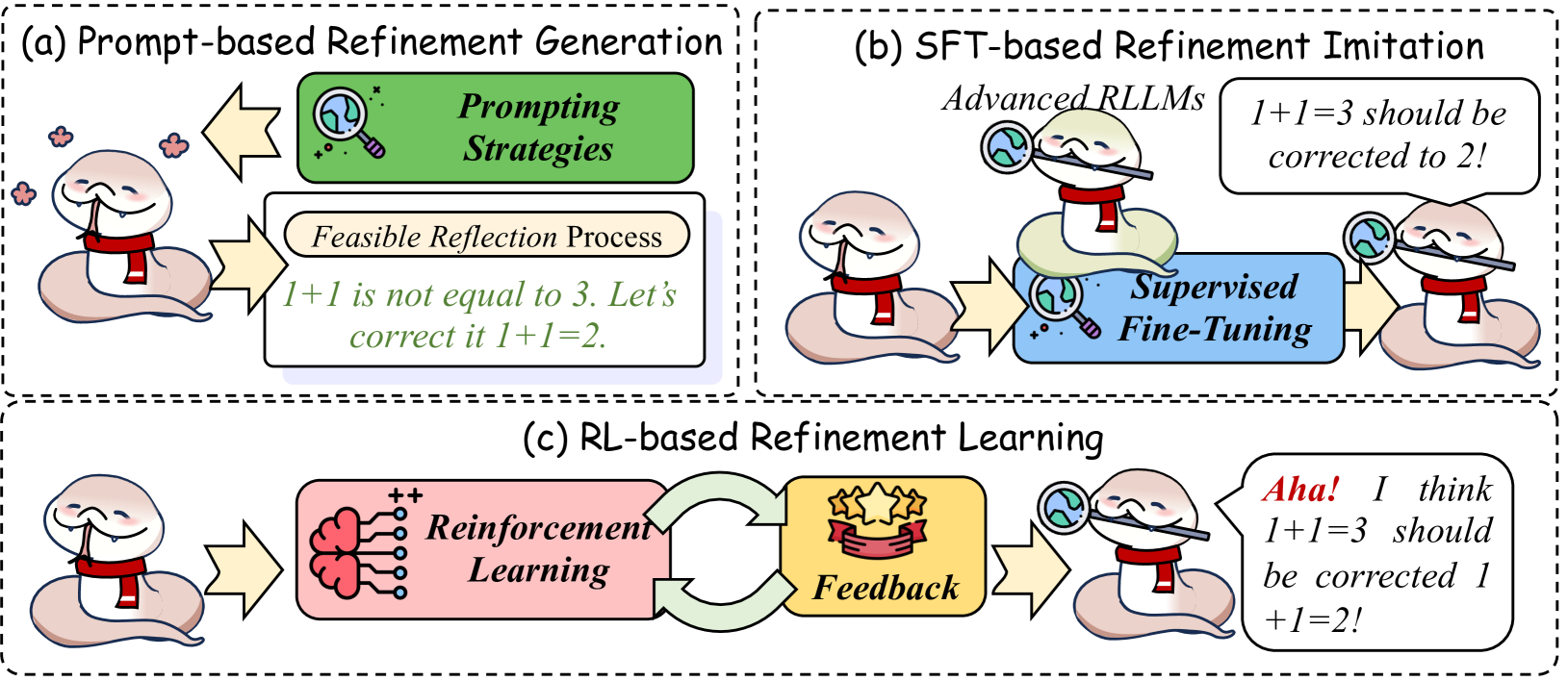
The image presents a comparative diagram illustrating three different methods for refining language model outputs: Prompt-based Refinement Generation, Supervised Fine-Tuning (SFT)-based Refinement Imitation, and Reinforcement Learning (RL)-based Refinement Learning. Each method is visually represented with a cartoonish depiction of a character (a stylized head) interacting with various elements symbolizing the process. The diagram is divided into three distinct sections, labeled (a), (b), and (c), each enclosed within a dashed-line border.
### Components/Axes
The diagram doesn't have traditional axes. Instead, it uses visual elements to represent the flow of information and the key components of each refinement method. The key components are:
* **Prompting Strategies:** Associated with (a) Prompt-based Refinement Generation.
* **Supervised Fine-Tuning:** Associated with (b) SFT-based Refinement Imitation.
* **Reinforcement Learning:** Associated with (c) RL-based Refinement Learning.
* **Feedback:** Associated with (c) RL-based Refinement Learning.
* **Feasible Reflection Process:** Associated with (a) Prompt-based Refinement Generation.
* **Advanced RLLMs:** Associated with (b) SFT-based Refinement Imitation.
### Detailed Analysis or Content Details
**(a) Prompt-based Refinement Generation:**
* A yellow arrow points downwards towards a green board with a red "X" on it, labeled "Prompting Strategies".
* A speech bubble originating from the character states: "1 + 1 is not equal to 3. Let's correct it 1 + 1 = 2."
* An oval shape labeled "Feasible Reflection Process" surrounds the character and the speech bubble.
* Scattered pink flower icons are present around the character.
**(b) SFT-based Refinement Imitation:**
* A blue magnifying glass encircles the character's head, labeled "Advanced RLLMs".
* A speech bubble originating from the character states: "1+1=3 should be corrected to 2!".
* An oval shape labeled "Supervised Fine-Tuning" surrounds the character and the speech bubble.
* A purple gear icon is present near the character's head.
**(c) RL-based Refinement Learning:**
* A green brain icon with "++" symbols represents "Reinforcement Learning".
* A red starburst icon represents "Feedback".
* A curved green arrow connects the brain icon to the starburst icon, and then to the character.
* A speech bubble originating from the character states: "Aha! I think 1+1=3 should be corrected 1 + 1 = 2!".
### Key Observations
* All three methods aim to correct the same incorrect equation: "1 + 1 = 3".
* The methods differ in how they approach the correction process. Prompting relies on explicit strategies, SFT on imitation, and RL on learning from feedback.
* The visual style is consistent across all three sections, using cartoonish representations to convey the concepts.
* The use of speech bubbles emphasizes the character's internal reasoning or output.
### Interpretation
The diagram illustrates different approaches to refining the output of a language model. The core problem is correcting a simple arithmetic error ("1 + 1 = 3"). Each method represents a different paradigm in machine learning:
* **Prompt-based Refinement:** This method relies on carefully crafted prompts to guide the model towards the correct answer. The "Prompting Strategies" element suggests that the quality of the prompt is crucial. The "Feasible Reflection Process" indicates a step-by-step reasoning approach.
* **SFT-based Refinement:** This method leverages supervised learning, where the model learns to imitate correct responses. The "Advanced RLLMs" element suggests that this method builds upon existing large language models. The "Supervised Fine-Tuning" element highlights the need for labeled data.
* **RL-based Refinement:** This method uses reinforcement learning, where the model learns through trial and error and receives feedback on its performance. The "Reinforcement Learning" and "Feedback" elements emphasize the iterative nature of this approach.
The diagram suggests that each method has its strengths and weaknesses. Prompting is simple but may require significant prompt engineering. SFT requires labeled data but can be effective if the data is high-quality. RL can learn complex behaviors but may be unstable and require careful tuning. The consistent correction ("1 + 1 = 2") across all methods highlights the desired outcome, regardless of the approach. The diagram is a conceptual illustration rather than a quantitative analysis, focusing on the high-level principles of each refinement technique.