## Diagram: AI Model Refinement Strategies
### Overview
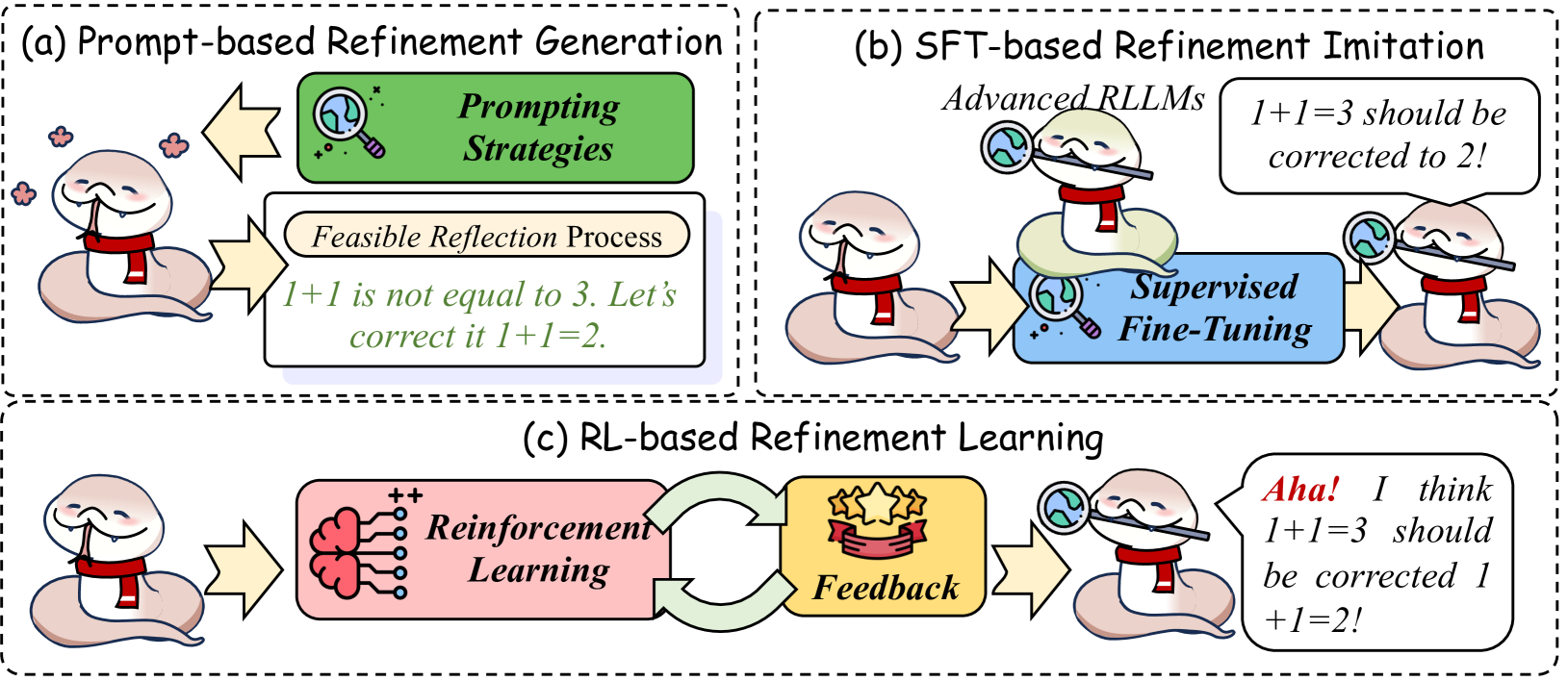
The diagram illustrates three distinct approaches to refining AI model outputs through iterative correction processes. It uses a cartoon snake mascot with a red scarf to represent the AI agent undergoing refinement. Three labeled sections (a, b, c) demonstrate different technical methodologies for error correction and self-improvement.
### Components/Axes
1. **Section (a): Prompt-based Refinement Generation**
- **Prompting Strategies** (green box with magnifying glass icon)
- **Feasible Reflection Process** (beige box with text)
- Flow: Snake → Prompting Strategies → Reflection Process → Corrected Output
2. **Section (b): SFT-based Refinement Imitation**
- **Advanced RLLMs** (text above snake with magnifying glass)
- **Supervised Fine-Tuning** (blue box with magnifying glass icon)
- Flow: Snake → Advanced RLLMs → Supervised Fine-Tuning → Corrected Output
3. **Section (c): RL-based Refinement Learning**
- **Reinforcement Learning** (pink box with neural network icon)
- **Feedback** (gold box with star icon)
- Flow: Snake → Reinforcement Learning → Feedback → Self-Correction
### Detailed Analysis
- **Section (a)** demonstrates basic error correction through explicit prompting:
- Input: "1+1 is not equal to 3. Let's correct it 1+1=?"
- Output: "1+1=2"
- **Section (b)** shows advanced imitation learning:
- Input: "1+1=3 should be corrected to 2!"
- Process: Supervised fine-tuning of advanced RLLMs (Reinforcement Learning Language Models)
- **Section (c)** illustrates autonomous self-correction:
- Input: "Aha! I think 1+1=3 should be corrected 1+1=2!"
- Process: Reinforcement learning with feedback loops
### Key Observations
1. All sections use the snake mascot to represent the AI agent's progression from error-prone to self-correcting
2. Magnifying glass icons consistently represent analytical processes across sections
3. Color coding differentiates methodologies:
- Green: Prompt-based
- Blue: Supervised fine-tuning
- Pink: Reinforcement learning
4. Feedback loops are only present in the RL-based approach (section c)
### Interpretation
This diagram reveals a progression from basic to advanced refinement techniques:
1. **Prompt-based (a)** requires explicit human guidance for corrections
2. **SFT-based (b)** introduces imitation learning through supervised fine-tuning of advanced models
3. **RL-based (c)** achieves autonomous improvement through reinforcement learning and feedback
The snake's increasing self-awareness ("Aha!") in section (c) suggests that reinforcement learning enables meta-cognitive capabilities. The magnifying glass motif across all sections implies that analytical scrutiny remains central to all refinement strategies, though its application becomes more sophisticated from sections (a) to (c).
The absence of quantitative metrics suggests this is a conceptual framework rather than an empirical study. The red scarf may symbolize the AI's "training" status, with the scarf's prominence decreasing as refinement progresses from sections (a) to (c).