\n
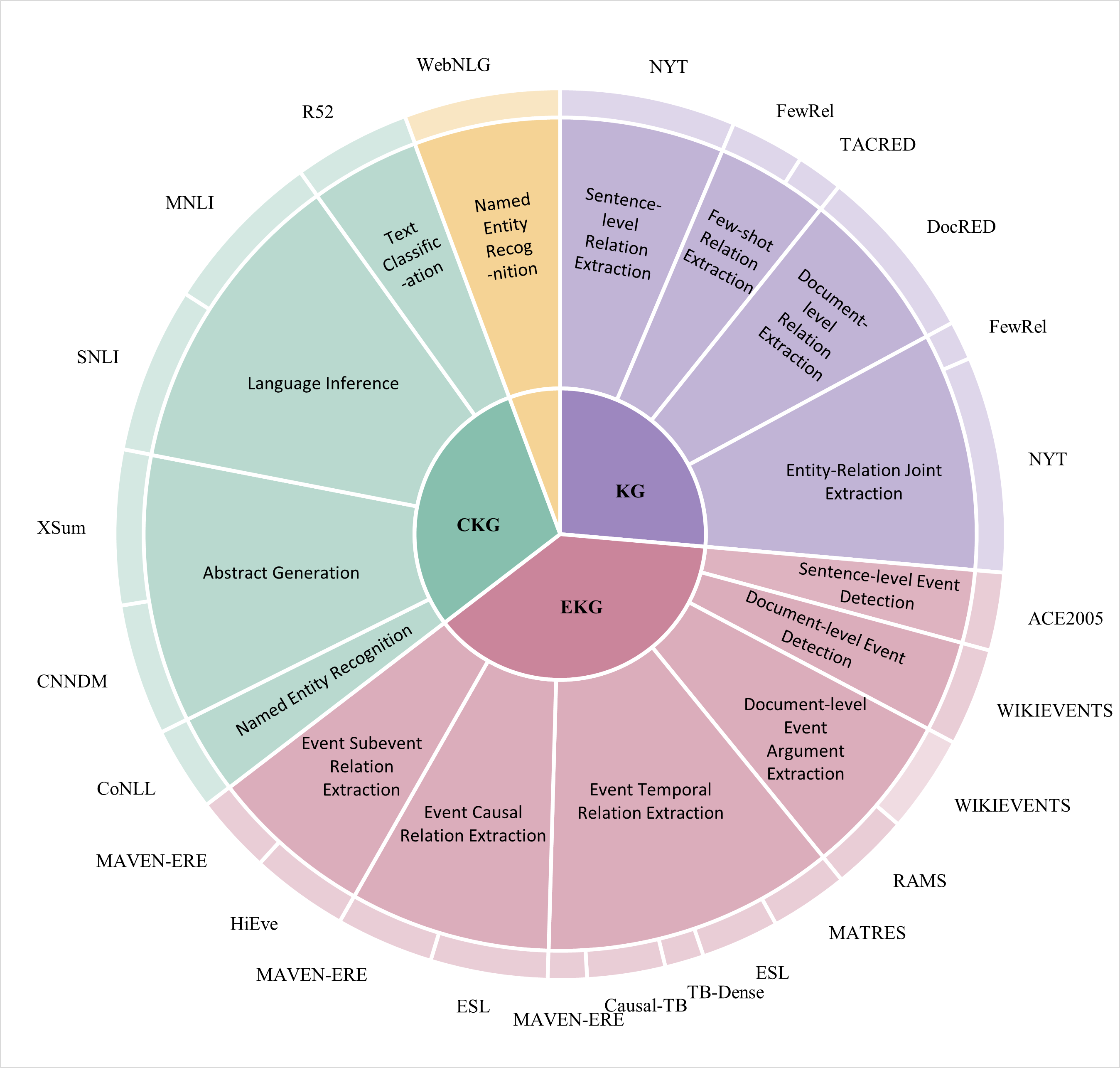
## Sunburst Diagram: Knowledge Graph Task and Dataset Taxonomy
### Overview
This image is a multi-level circular sunburst chart (or radial treemap) that categorizes Natural Language Processing (NLP) tasks and their associated benchmark datasets. The diagram is organized hierarchically, with three primary categories at the center branching out into specific tasks and then to the datasets used for those tasks. The entire diagram is presented on a plain white background.
### Components/Axes
The diagram has three concentric rings or layers:
1. **Innermost Ring (Core Categories):** Three primary segments labeled **CKG** (green), **KG** (purple), and **EKG** (pink). These likely stand for different types of Knowledge Graphs (e.g., Common/Conceptual KG, General KG, Event KG).
2. **Middle Ring (Task Categories):** Each core category is subdivided into specific NLP task types. These are the main colored segments radiating from the center.
3. **Outer Ring (Datasets):** The outermost ring lists specific benchmark datasets corresponding to the tasks in the middle ring. These are represented as smaller, lighter-colored segments attached to their parent task.
**Color Coding:**
* **Green (CKG):** Tasks related to common or conceptual knowledge.
* **Purple (KG):** Tasks related to general knowledge graph construction and reasoning.
* **Pink (EKG):** Tasks related to event knowledge graphs.
* **Yellow (Sub-section of CKG):** A distinct color highlights the "Named Entity Recognition" task under CKG.
### Detailed Analysis
#### **Section 1: CKG (Green, Left Hemisphere)**
* **Core Label:** CKG (center-left).
* **Tasks & Associated Datasets (moving clockwise from top):**
1. **Text Classification** -> Dataset: **R52** (outer ring, top-left).
2. **Named Entity Recognition** (Yellow segment) -> Dataset: **WebNLG** (outer ring, top).
3. **Language Inference** -> Datasets: **MNLI**, **SNLI** (outer ring, left).
4. **Abstract Generation** -> Datasets: **XSum**, **CNNDM** (outer ring, left-bottom).
5. **Named Entity Recognition** (Green segment) -> Datasets: **CoNLL**, **MAVEN-ERE** (outer ring, bottom-left).
#### **Section 2: KG (Purple, Top-Right Hemisphere)**
* **Core Label:** KG (center-top-right).
* **Tasks & Associated Datasets (moving clockwise from top):**
1. **Sentence-level Relation Extraction** -> Datasets: **NYT**, **FewRel** (outer ring, top-right).
2. **Few-shot Relation Extraction** -> Datasets: **TACRED**, **DocRED** (outer ring, top-right).
3. **Document-level Relation Extraction** -> Dataset: **FewRel** (outer ring, right).
4. **Entity-Relation Joint Extraction** -> Dataset: **NYT** (outer ring, right).
#### **Section 3: EKG (Pink, Bottom-Right Hemisphere)**
* **Core Label:** EKG (center-bottom-right).
* **Tasks & Associated Datasets (moving clockwise from right):**
1. **Sentence-level Event Detection** -> Dataset: **ACE2005** (outer ring, right).
2. **Document-level Event Detection** -> Dataset: **WIKIEVENTS** (outer ring, right-bottom).
3. **Document-level Event Argument Extraction** -> Dataset: **WIKIEVENTS** (outer ring, bottom-right).
4. **Event Temporal Relation Extraction** -> Datasets: **RAMS**, **MATRES** (outer ring, bottom-right).
5. **Event Causal Relation Extraction** -> Datasets: **ESL**, **TB-Dense**, **Causal-TB** (outer ring, bottom).
6. **Event Subevent Relation Extraction** -> Datasets: **MAVEN-ERE**, **HiEve**, **ESL**, **MAVEN-ERE** (outer ring, bottom-left).
### Key Observations
1. **Hierarchical Structure:** The diagram clearly shows a three-tiered taxonomy: Knowledge Graph Type -> NLP Task -> Benchmark Dataset.
2. **Task Distribution:** The "EKG" (Event KG) section contains the most细分 tasks (6 distinct tasks), suggesting a rich and complex sub-field focused on events.
3. **Dataset Reuse:** Several datasets appear under multiple tasks. For example:
* **NYT** is used for both "Sentence-level Relation Extraction" (under KG) and "Entity-Relation Joint Extraction" (under KG).
* **MAVEN-ERE** is used for "Named Entity Recognition" (under CKG) and "Event Subevent Relation Extraction" (under EKG).
* **FewRel** is used for both "Sentence-level" and "Few-shot Relation Extraction."
* **WIKIEVENTS** is used for both "Document-level Event Detection" and "Document-level Event Argument Extraction."
4. **Visual Grouping:** Tasks and datasets are visually grouped by color and radial proximity, making it easy to see which tasks belong to which core KG type.
### Interpretation
This diagram serves as a **conceptual map or taxonomy for the field of Knowledge Graph-Related NLP**. It visually organizes the research landscape by first distinguishing between three fundamental types of knowledge representation (Common, General, Event), then detailing the specific extraction, inference, or generation tasks associated with each, and finally grounding those tasks in the concrete benchmark datasets used to evaluate progress.
The structure implies that the choice of KG type (CKG, KG, EKG) fundamentally shapes the nature of the downstream NLP tasks. For instance, tasks under "EKG" are inherently about dynamic occurrences (events, their arguments, temporal and causal links), while tasks under "CKG" focus more on static entity and text understanding.
The reuse of datasets across different tasks (like NYT or MAVEN-ERE) highlights that a single, rich dataset can support multiple research questions and evaluation paradigms. It also suggests potential for multi-task learning or comparative analysis across tasks using the same underlying data.
Overall, this is a **reference tool for researchers** to understand the scope of KG-focused NLP, identify relevant benchmarks for a specific task, and see the relationships between different sub-fields. It emphasizes the structured, hierarchical nature of knowledge-driven language understanding.