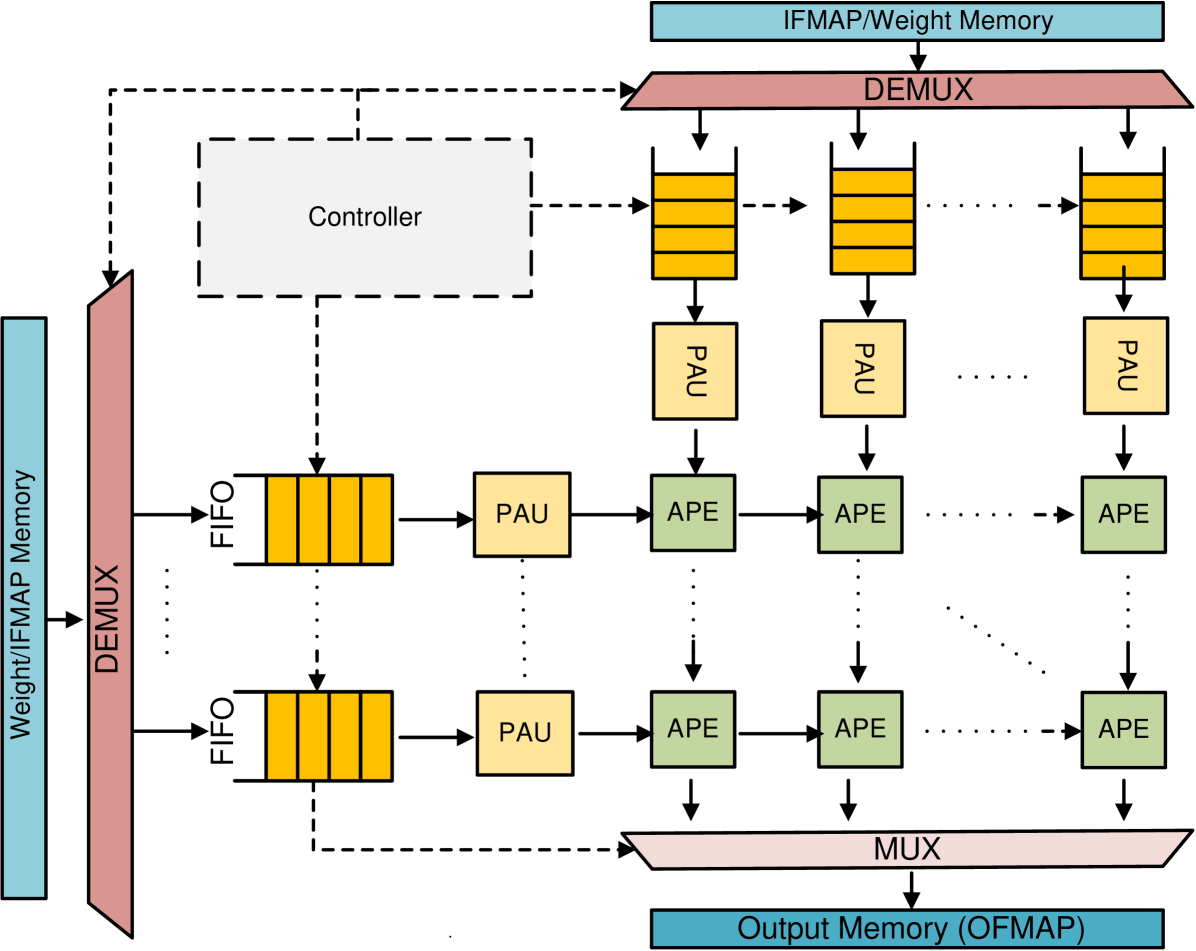
## Block Diagram: Neural Network Processing Pipeline
### Overview
The diagram illustrates a multi-stage processing pipeline for neural network operations, featuring parallel computation paths, data routing, and memory management. Key components include demultiplexers (DEMUX), processing units (PAU/APE), memory blocks, and control logic.
### Components/Axes
1. **Input Memory**:
- **Weight/IFMAP Memory** (blue block on left)
- **DEMUX** (pink block) splits input into parallel paths
2. **Processing Units**:
- **PAU** (yellow blocks): Parallel Processing Units
- **APE** (green blocks): Arithmetic Processing Elements
3. **Control Logic**:
- **Controller** (white box) manages data flow
- **IFMAP/Weight Memory** (top blue block) stores input data
4. **Output Management**:
- **MUX** (pink block) merges processed data
- **Output Memory (OFMAP)** (bottom blue block) stores final results
### Detailed Analysis
1. **Data Flow Path**:
- Input from Weight/IFMAP Memory → DEMUX → 6 parallel paths
- Each path contains:
- FIFO buffer → PAU → APE
- Processed data from 6 APE units → MUX → Output Memory
2. **Component Connections**:
- DEMUX splits input into 3 paths (top) and 3 paths (bottom)
- Each path contains 2 PAUs and 2 APEs in sequence
- MUX combines all 6 APE outputs into single stream
3. **Memory Architecture**:
- Dual memory hierarchy:
- Top: IFMAP/Weight Memory (input data)
- Bottom: Output Memory (OFMAP) for results
### Key Observations
1. **Parallelism**:
- 6 parallel computation paths enable simultaneous processing
- Each path processes 1/6th of input data independently
2. **Pipelining**:
- Data flows through PAU → APE sequence in each path
- Suggests multi-stage processing (e.g., convolution → activation)
3. **Control Mechanism**:
- Controller coordinates DEMUX/MUX operations
- Implies synchronized data routing and timing
### Interpretation
This architecture appears designed for efficient neural network inference, particularly for convolutional networks. The DEMUX/MUX combination enables:
- **Bandwidth Optimization**: Parallel data streams reduce memory contention
- **Compute Efficiency**: PAU/APE specialization suggests hardware acceleration
- **Scalability**: Modular design allows adding more processing paths
The Controller's role in managing DEMUX/MUX operations indicates a need for precise timing control, likely to handle pipeline synchronization and data dependencies. The FIFO buffers suggest asynchronous operation between processing stages, allowing for variable latency between PAU and APE units.