# Technical Document Extraction: FSM and LLM Decoding Processes
## Diagram Components and Flow Analysis
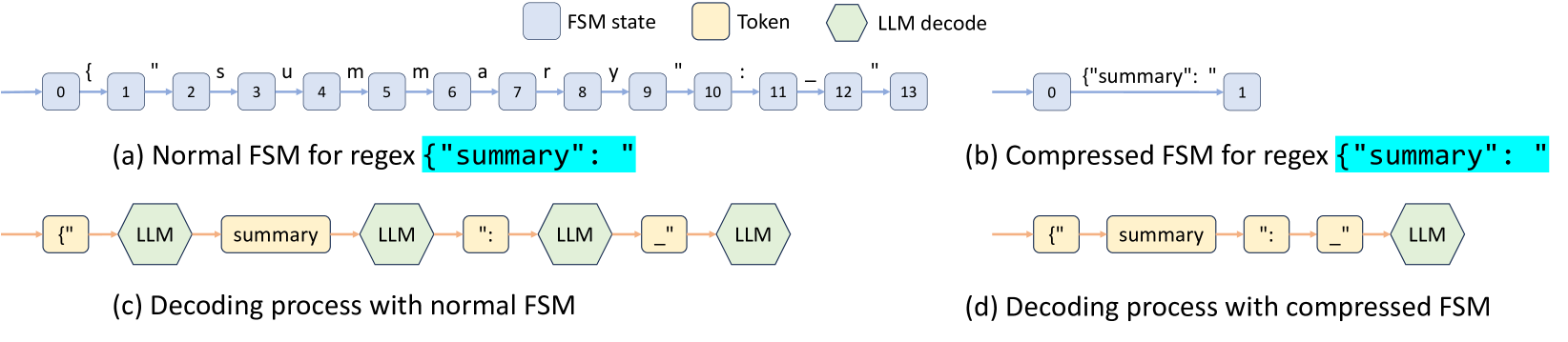
### Diagram (a): Normal FSM for Regex `{"summary": ""}`
- **FSM States**: 14 states labeled 0–13 (blue squares).
- **Transitions**: Sequential transitions between states (e.g., 0 → 1 → 2 → ... → 13).
- **Regex Highlight**: `{"summary": ""}` (cyan highlight).
- **Tokens**: Single token `"{"` (yellow rectangle) initiating the FSM.
### Diagram (b): Compressed FSM for Regex `{"summary": ""}`
- **FSM States**: 2 states labeled 0–1 (blue squares).
- **Transitions**: Direct transition from state 0 to 1.
- **Regex Highlight**: `{"summary": ""}` (cyan highlight).
- **Tokens**: Single token `"{"` (yellow rectangle) initiating the FSM.
### Diagram (c): Decoding Process with Normal FSM
- **Components**:
- **Token Input**: `"{"` (yellow rectangle).
- **LLM Decodes**: 5 hexagonal nodes labeled "LLM Decode".
- **FSM Integration**:
- Token `"{"` → LLM Decode → `"summary"` (token) → LLM Decode → `":"` (token) → LLM Decode → `" "` (token) → LLM Decode → Final output `{"summary": ""}`.
- **Flow**: Token → LLM Decode → Token → LLM Decode → Token → LLM Decode → Token → LLM Decode → Final Regex Output.
### Diagram (d): Decoding Process with Compressed FSM
- **Components**:
- **Token Input**: `"{"` (yellow rectangle).
- **LLM Decodes**: 3 hexagonal nodes labeled "LLM Decode".
- **FSM Integration**:
- Token `"{"` → LLM Decode → `"summary"` (token) → LLM Decode → `":"` (token) → LLM Decode → Final output `{"summary": ""}`.
- **Flow**: Token → LLM Decode → Token → LLM Decode → Token → LLM Decode → Final Regex Output.
## Key Observations
1. **FSM Compression**:
- Normal FSM: 14 states (0–13) for regex `{"summary": ""}`.
- Compressed FSM: 2 states (0–1) for the same regex, reducing complexity.
2. **LLM Decoding**:
- Normal FSM: 5 LLM decodes required for full regex reconstruction.
- Compressed FSM: 3 LLM decodes required, streamlining the process.
3. **Token Handling**:
- Both processes start with the token `"{"` and end with the regex `{"summary": ""}`.
- Compressed FSM merges intermediate steps, reducing token-LLM interactions.
## Legend and Color Mapping
- **Blue Squares**: FSM States (Normal/Compressed).
- **Yellow Rectangles**: Tokens (e.g., `"{"`, `"summary"`, `":"`).
- **Green Hexagons**: LLM Decode Nodes.
- **Cyan Highlight**: Regex `{"summary": ""}` (target output).
## Data Points and Trends
- **Normal FSM**:
- Longer path (14 states) with sequential token processing.
- Higher computational overhead due to multiple LLM decodes.
- **Compressed FSM**:
- Shorter path (2 states) with direct transitions.
- Reduced LLM decodes (3 vs. 5), improving efficiency.
## Conclusion
The diagrams illustrate two approaches to regex decoding:
1. **Normal FSM**: Detailed state transitions with frequent LLM integration.
2. **Compressed FSM**: Optimized state reduction and fewer LLM decodes for efficiency.
Both methods achieve the same output `{"summary": ""}`, but the compressed FSM offers a more streamlined process.