# Technical Document Extraction: FSM and LLM Decoding Comparison
This document describes a technical diagram illustrating the optimization of Finite State Machines (FSM) for Large Language Model (LLM) decoding processes, specifically for regex-constrained generation.
## 1. Legend and Component Definitions
The diagram uses color-coded and shape-coded blocks to represent different stages of the process:
* **FSM state (Light Blue Rectangle):** Represents a discrete state within a Finite State Machine.
* **Token (Light Yellow Rectangle):** Represents a specific string or character sequence processed as a unit.
* **LLM decode (Light Green Hexagon):** Represents the computational step where the Large Language Model generates/decodes a token.
---
## 2. Diagram Analysis by Section
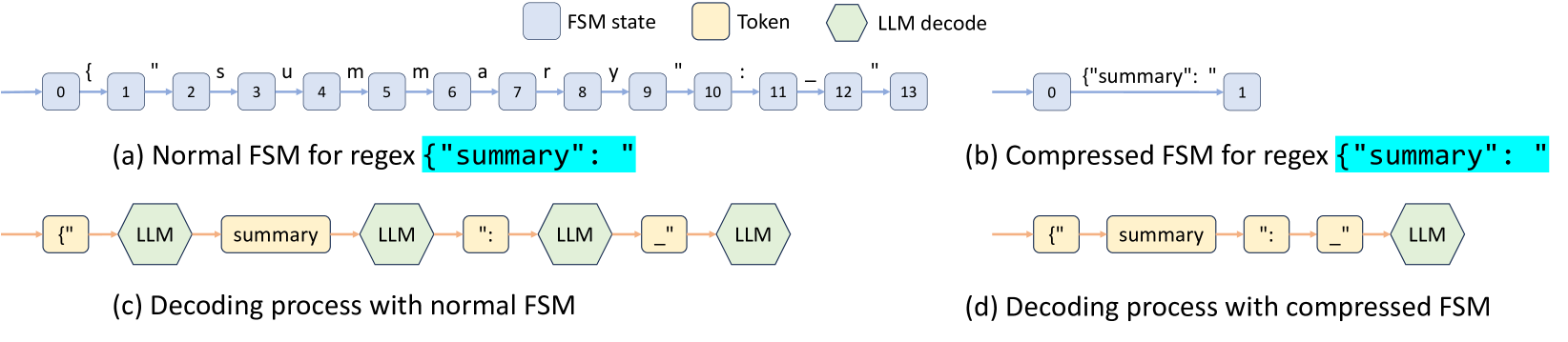
### Section (a): Normal FSM for regex `{"summary": "`
This section shows a linear, character-by-character state transition for a specific JSON-like string.
* **Flow:** A sequence of 14 states (numbered 0 through 13) connected by blue arrows.
* **Transitions:** Each arrow represents a single character transition:
* 0 → 1: `{`
* 1 → 2: `"`
* 2 → 3: `s`
* 3 → 4: `u`
* 4 → 5: `m`
* 5 → 6: `m`
* 6 → 7: `a`
* 7 → 8: `r`
* 8 → 9: `y`
* 9 → 10: `"`
* 10 → 11: `:`
* 11 → 12: `_` (space character)
* 12 → 13: `"`
### Section (b): Compressed FSM for regex `{"summary": "`
This section demonstrates the optimization of the FSM by collapsing multiple character transitions into a single state jump.
* **Flow:** A direct transition from state **0** to state **1**.
* **Transition Label:** The entire string `{"summary": "` is handled in a single transition step.
### Section (c): Decoding process with normal FSM
This section illustrates the interaction between the LLM and the unoptimized FSM.
* **Sequence:**
1. **Token:** `{"`
2. **LLM decode**
3. **Token:** `summary`
4. **LLM decode**
5. **Token:** `":`
6. **LLM decode**
7. **Token:** `_"` (space and quote)
8. **LLM decode**
* **Trend:** The process is fragmented, requiring four separate LLM decoding steps to complete the sequence because the FSM operates at a fine-grained level.
### Section (d): Decoding process with compressed FSM
This section illustrates the interaction between the LLM and the optimized FSM.
* **Sequence:**
1. **Token:** `{"`
2. **Token:** `summary`
3. **Token:** `":`
4. **Token:** `_"` (space and quote)
5. **LLM decode**
* **Trend:** The tokens are processed sequentially without interruption. The LLM decoding step only occurs once at the end of the pre-defined sequence.
---
## 3. Summary of Key Information
* **Objective:** To compare "Normal" vs. "Compressed" FSMs in the context of LLM decoding.
* **Key Data Point:** The compressed FSM (b) reduces a 13-step character transition into a single transition.
* **Process Efficiency:** The decoding process with a compressed FSM (d) significantly reduces the number of LLM decoding calls compared to the normal process (c), which requires an LLM call after almost every token segment.
* **Textual Content:** The primary regex being processed is `{"summary": "`. Note that in the diagram, the space character is represented by an underscore `_` in the transition labels.