## Table: LM Answer Identification Example
### Overview
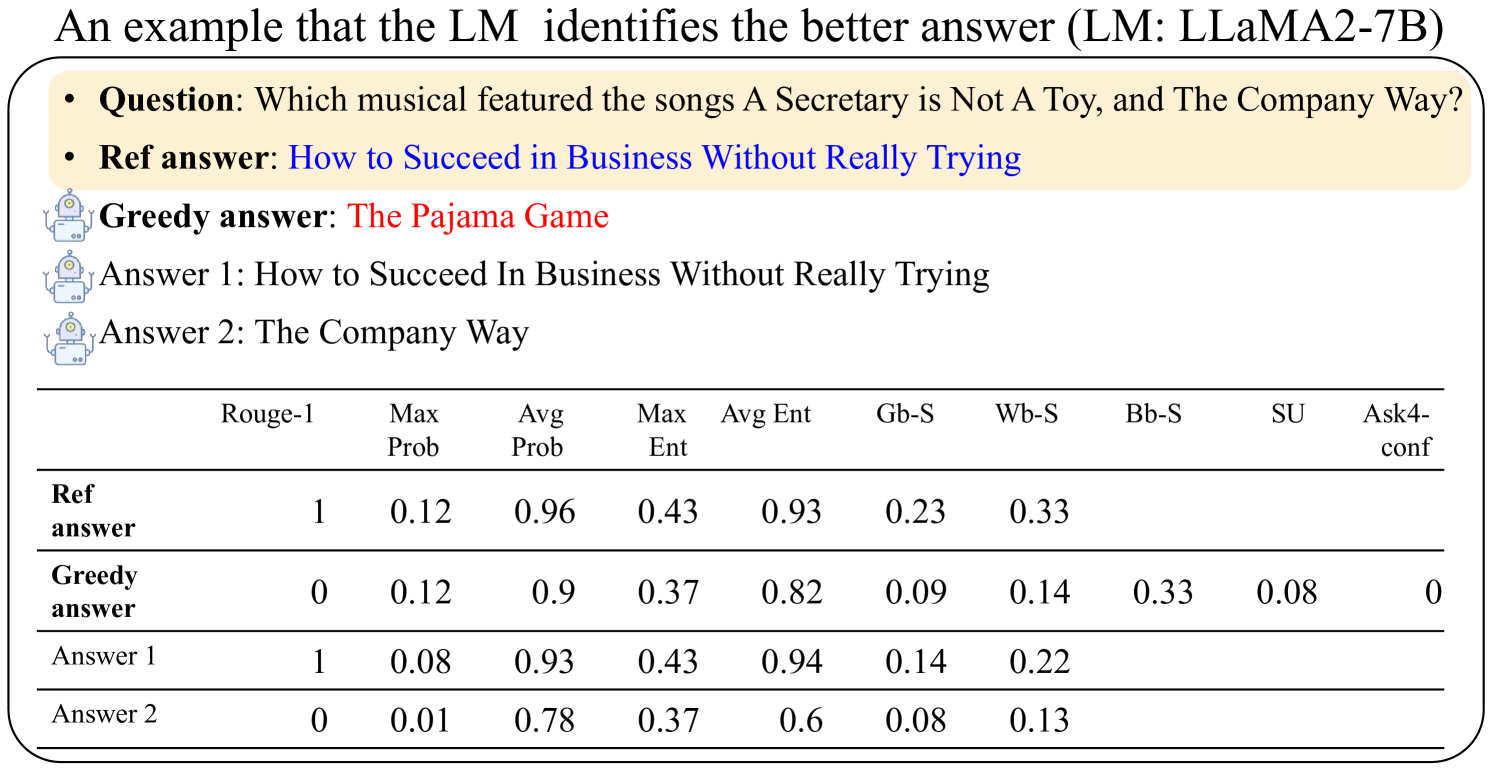
The image presents an example of how a Language Model (LM), specifically LLaMA2-7B, identifies the better answer to a question. It includes the question, a reference answer, a greedy answer, and two other possible answers. A table provides metrics for each answer, including Rouge-1 score, maximum probability, average probability, maximum entropy, average entropy, Gb-S, Wb-S, Bb-S, SU, and Ask4-conf.
### Components/Axes
* **Title:** An example that the LM identifies the better answer (LM: LLaMA2-7B)
* **Question:** Which musical featured the songs A Secretary is Not A Toy, and The Company Way?
* **Answers:**
* Ref answer: How to Succeed in Business Without Really Trying
* Greedy answer: The Pajama Game
* Answer 1: How to Succeed In Business Without Really Trying
* Answer 2: The Company Way
* **Table Headers:**
* Rouge-1
* Max Prob
* Avg Prob
* Max Ent
* Avg Ent
* Gb-S
* Wb-S
* Bb-S
* SU
* Ask4-conf
* **Table Rows:**
* Ref answer
* Greedy answer
* Answer 1
* Answer 2
### Detailed Analysis or ### Content Details
The table presents the following data:
| | Rouge-1 | Max Prob | Avg Prob | Max Ent | Avg Ent | Gb-S | Wb-S | Bb-S | SU | Ask4-conf |
| :-------------------- | :------ | :------- | :------- | :------ | :------ | :--- | :--- | :--- | :--- | :-------- |
| Ref answer | 1 | 0.12 | 0.96 | 0.43 | 0.93 | 0.23 | 0.33 | | | |
| Greedy answer | 0 | 0.12 | 0.9 | 0.37 | 0.82 | 0.09 | 0.14 | 0.33 | 0.08 | 0 |
| Answer 1 | 1 | 0.08 | 0.93 | 0.43 | 0.94 | 0.14 | 0.22 | | | |
| Answer 2 | 0 | 0.01 | 0.78 | 0.37 | 0.6 | 0.08 | 0.13 | | | |
### Key Observations
* The "Ref answer" and "Answer 1" have the highest Rouge-1 scores (1), indicating they are the closest to the reference answer based on the Rouge-1 metric.
* The "Ref answer" has the highest average probability (0.96).
* The "Greedy answer" has the lowest Ask4-conf score (0).
* "Answer 2" has the lowest Max Prob (0.01) and Avg Prob (0.78)
### Interpretation
The table provides a quantitative comparison of different answers generated by the LM against a reference answer. The metrics suggest that the LM identifies "Ref answer" and "Answer 1" as better answers, as indicated by their higher Rouge-1 scores and average probabilities. The "Greedy answer" and "Answer 2" perform worse according to these metrics. The data demonstrates how different metrics can be used to evaluate the quality of answers generated by a language model.