\n
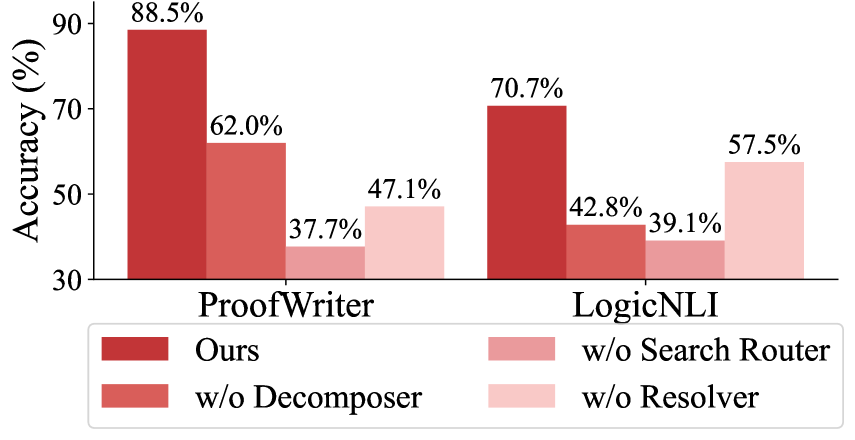
## Grouped Bar Chart: Model Ablation Study on ProofWriter and LogicNLI Datasets
### Overview
The image displays a grouped bar chart comparing the accuracy (in percentage) of a proposed model ("Ours") against three ablated versions on two distinct datasets: ProofWriter and LogicNLI. The chart visually demonstrates the performance impact of removing specific model components.
### Components/Axes
* **Chart Type:** Grouped bar chart.
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 30 to 90, with major tick marks at 30, 50, 70, and 90.
* **X-Axis:** Contains two primary categorical groups: "ProofWriter" (left group) and "LogicNLI" (right group).
* **Legend:** Positioned at the bottom center of the chart. It defines four model variants by color:
* **Dark Red:** "Ours"
* **Medium Red:** "w/o Decomposer"
* **Light Red:** "w/o Search Router"
* **Very Light Pink:** "w/o Resolver"
* **Data Labels:** Each bar has its exact accuracy percentage value displayed directly above it.
### Detailed Analysis
**ProofWriter Dataset (Left Group):**
1. **Ours (Dark Red, leftmost bar):** 88.5% accuracy. This is the tallest bar in the entire chart.
2. **w/o Decomposer (Medium Red, second bar):** 62.0% accuracy.
3. **w/o Search Router (Light Red, third bar):** 37.7% accuracy. This is the shortest bar in the ProofWriter group.
4. **w/o Resolver (Very Light Pink, rightmost bar):** 47.1% accuracy.
**LogicNLI Dataset (Right Group):**
1. **Ours (Dark Red, leftmost bar):** 70.7% accuracy. This is the tallest bar in the LogicNLI group.
2. **w/o Decomposer (Medium Red, second bar):** 42.8% accuracy. This is the shortest bar in the LogicNLI group.
3. **w/o Search Router (Light Red, third bar):** 39.1% accuracy.
4. **w/o Resolver (Very Light Pink, rightmost bar):** 57.5% accuracy.
**Trend Verification:**
* In both datasets, the "Ours" model (dark red) shows a clear upward trend compared to all ablated versions, achieving the highest accuracy.
* The removal of any component leads to a significant performance drop. The magnitude of the drop varies by dataset and component.
* For ProofWriter, the performance order from highest to lowest is: Ours > w/o Decomposer > w/o Resolver > w/o Search Router.
* For LogicNLI, the performance order from highest to lowest is: Ours > w/o Resolver > w/o Decomposer > w/o Search Router.
### Key Observations
1. **Consistent Superiority:** The full model ("Ours") significantly outperforms all ablated variants on both tasks, indicating the combined value of all components.
2. **Component Criticality Varies by Task:**
* The **Search Router** appears to be the most critical component for the **ProofWriter** task, as its removal causes the largest accuracy drop (from 88.5% to 37.7%, a 50.8 percentage point decrease).
* The **Decomposer** appears to be the most critical component for the **LogicNLI** task, as its removal causes the largest drop (from 70.7% to 42.8%, a 27.9 percentage point decrease).
3. **Resolver's Role:** Removing the **Resolver** has the least severe impact among the ablations in both tasks, though the drop is still substantial. Interestingly, the model without the Resolver performs better on LogicNLI (57.5%) than the model without the Decomposer (42.8%), which is the opposite of the trend seen in ProofWriter.
4. **Overall Performance Gap:** The absolute performance gap between the full model and the best ablated version is larger for ProofWriter (88.5% vs. 62.0%, a 26.5-point gap) than for LogicNLI (70.7% vs. 57.5%, a 13.2-point gap).
### Interpretation
This ablation study provides strong evidence for the efficacy of the proposed model's architecture. The data suggests that the **Decomposer**, **Search Router**, and **Resolver** are not redundant; each contributes meaningfully to the model's overall reasoning capability, as measured by accuracy on these logical inference tasks.
The varying impact of component removal across datasets implies that the tasks (ProofWriter and LogicNLI) likely rely on different reasoning sub-skills. ProofWriter, which involves generating natural language proofs, seems heavily dependent on the **Search Router**—perhaps for navigating a knowledge base or proof space. LogicNLI, which involves classifying natural language inferences, seems more dependent on the **Decomposer**—likely for breaking down complex sentences into logical forms.
The fact that the full model achieves the highest score on both tasks demonstrates the robustness and generalizability of the integrated approach. The chart effectively argues that the proposed model's strength lies in the synergistic combination of its specialized components, and removing any one of them creates a significant bottleneck in performance.