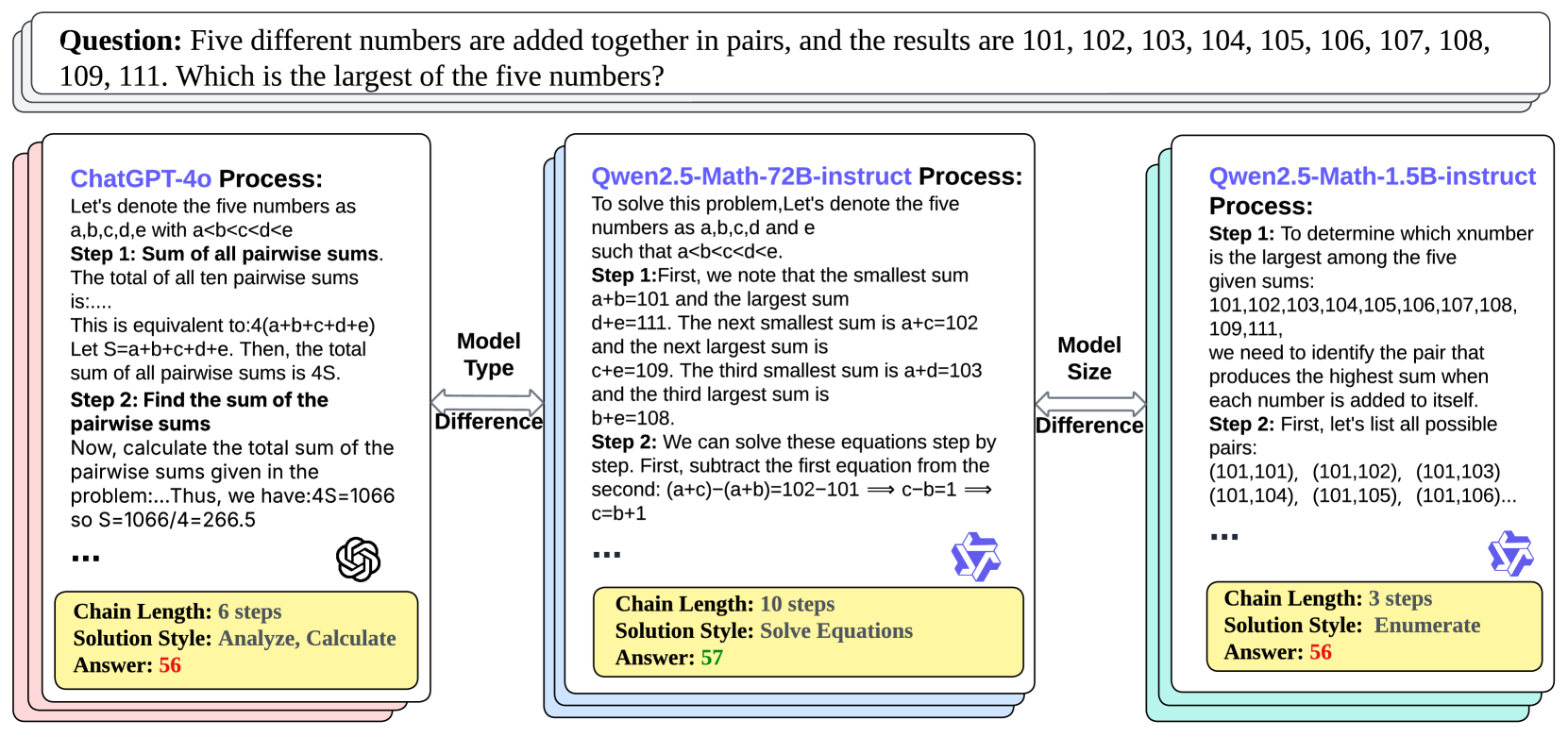
\n
## Diagram: Problem Solving Process Comparison
### Overview
The image presents a comparative diagram illustrating the problem-solving processes of three different Large Language Models (LLMs): ChatGPT-4o, Qwen2.5-Math-72B-instruct, and Qwen2.5-Math-1.5B-instruct. The problem posed is a mathematical word problem: "Five different numbers are added together in pairs, and the results are 101, 102, 103, 104, 105, 106, 107, 108, 109, 111. Which is the largest of the five numbers?". The diagram visually compares the steps, chain length, solution style, and answer provided by each model.
### Components/Axes
The diagram is structured into three main columns, one for each LLM. Each column is further divided into sections detailing:
* **Process:** A textual description of the model's approach to solving the problem.
* **Model Type:** Categorization of the model.
* **Chain Length:** The number of steps in the model's solution process.
* **Solution Style:** The method used to arrive at the solution.
* **Answer:** The numerical answer provided by the model.
A "Difference" label is present between each model's column.
### Detailed Analysis or Content Details
**ChatGPT-4o Process:**
* Step 1: Sum of all pairwise sums. The total of all ten pairwise sums is…
* Is equivalent to: 4(a+b+c+d+e)
* Let S=a+b+c+d+e. Then, the total sum of all pairwise sums is 4S.
* Step 2: Find the sum of the pairwise sums.
* Now, calculate the total sum of the pairwise sums given in the problem… Thus, we have: 4S=1066 so S=1066/4=266.5
* Chain Length: 6 steps
* Solution Style: Analyze, Calculate
* Answer: 56
**Qwen2.5-Math-72B-instruct Process:**
* To solve this problem, Let’s denote the five numbers as a,b,c,d and e such that a<b<c<d<e.
* Step 1: First, we note that the smallest sum a+b=101 and the largest sum d+e=111. The next smallest sum is a+c=102 and the next largest sum is c+d=109. The third smallest sum is a+d=103 and the third largest sum is b+e=108.
* Step 2: We can solve these equations step by step. First, subtract the first equation from the second: (a+c)-(a+b)=102-101 => c-b=1 => c=b+1
* Chain Length: 10 steps
* Solution Style: Solve Equations
* Answer: 57
**Qwen2.5-Math-1.5B-instruct Process:**
* Step 1: To determine which number is the largest among the five given sums: 101,102,103,104,105,106,107,108, 109,111,
* we need to identify the pair that produces the highest sum when each number is added to itself.
* Step 2: First, let’s list all possible pairs: (101,101), (101,102), (101,103) (101,104), (101,105), (101,106)…
* Chain Length: 3 steps
* Solution Style: Enumerate
* Answer: 56
### Key Observations
* The models differ significantly in their approach to solving the problem. ChatGPT-4o uses a summation-based approach, Qwen2.5-Math-72B-instruct employs an equation-solving method, and Qwen2.5-Math-1.5B-instruct attempts an enumeration strategy.
* The chain lengths vary considerably, with Qwen2.5-Math-72B-instruct having the longest chain (10 steps) and Qwen2.5-Math-1.5B-instruct the shortest (3 steps).
* Two models (ChatGPT-4o and Qwen2.5-Math-1.5B-instruct) arrive at the same answer (56), while Qwen2.5-Math-72B-instruct provides a different answer (57).
* The "Model Type" is labeled as "Difference" between each model, suggesting a comparison of their underlying architectures or capabilities.
### Interpretation
The diagram highlights the diversity in problem-solving strategies employed by different LLMs. The varying chain lengths and solution styles suggest different levels of complexity and efficiency in their reasoning processes. The discrepancy in answers indicates that not all models are equally reliable in solving mathematical problems. The diagram serves as a visual comparison of the strengths and weaknesses of each model, providing insights into their respective capabilities and limitations. The use of different solution styles (analytical calculation, equation solving, and enumeration) demonstrates the flexibility of LLMs in approaching the same problem from multiple angles. The fact that two models agree on the answer suggests a degree of convergence in their reasoning, while the outlier answer from Qwen2.5-Math-72B-instruct warrants further investigation. This comparison is valuable for understanding the current state of LLM technology and identifying areas for improvement.