TECHNICAL ASSET FINGERPRINT
03d22a9bc6de3201226cc731
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
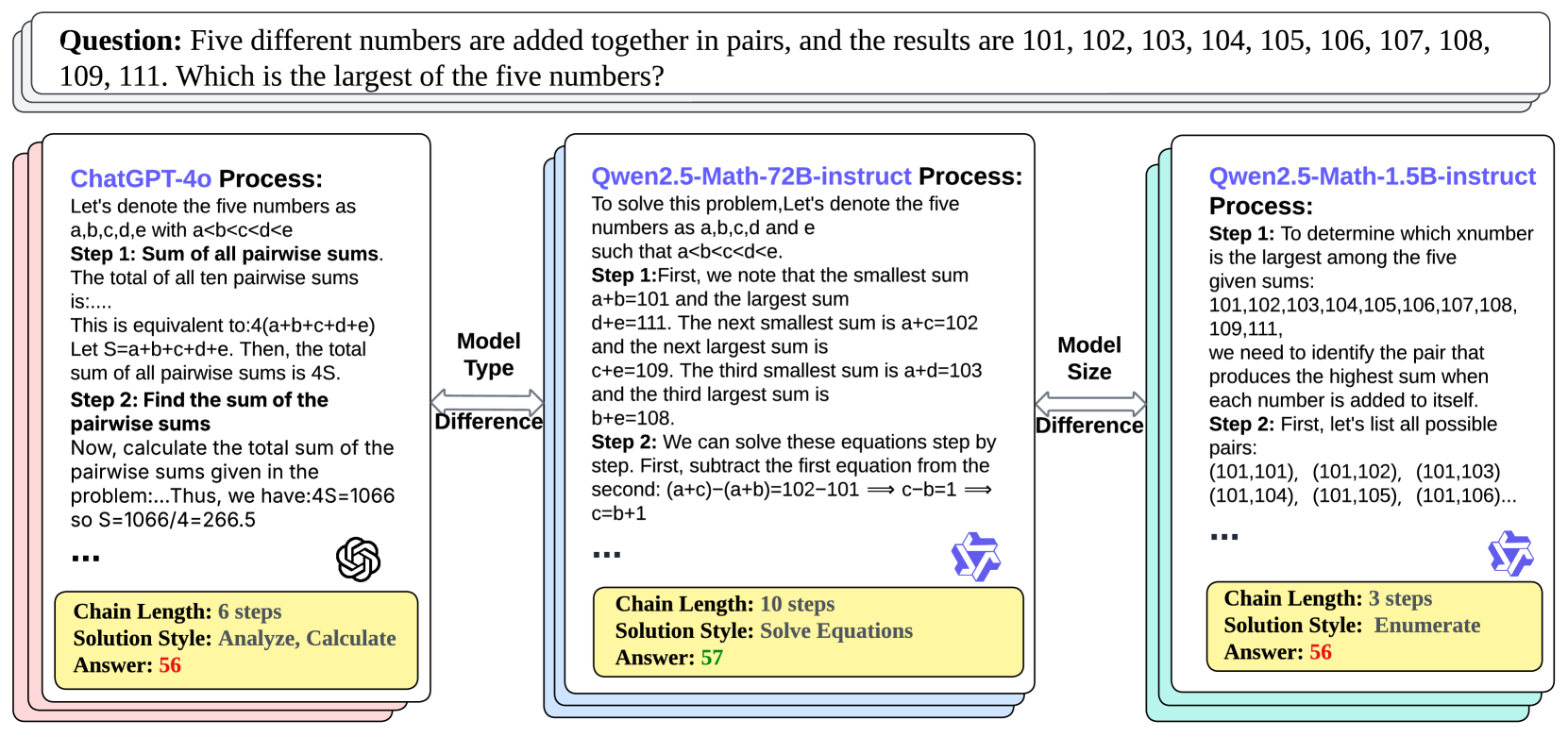
## Diagram: Comparative Problem-Solving Processes of Three AI Models
### Overview
The image is a technical diagram comparing the step-by-step reasoning processes of three different AI models (ChatGPT-4o, Qwen2.5-Math-72B-instruct, and Qwen2.5-Math-1.5B-instruct) as they solve the same mathematical word problem. The diagram visually contrasts their methodologies, chain lengths, solution styles, and final answers.
### Components/Axes
The diagram is structured into four main regions:
1. **Header (Top):** Contains the problem statement.
2. **Main Comparison Area (Center):** Three vertical panels, each dedicated to one model's process.
3. **Connecting Annotations (Between Panels):** Text and arrows indicating the axes of comparison.
4. **Footer (Bottom of each panel):** A summary box for each model.
**Labels and Text Elements:**
* **Problem Statement (Top):** "Question: Five different numbers are added together in pairs, and the results are 101, 102, 103, 104, 105, 106, 107, 108, 109, 111. Which is the largest of the five numbers?"
* **Model Panel Headers (Left to Right):**
* "ChatGPT-4o Process:" (in blue text)
* "Qwen2.5-Math-72B-instruct Process:" (in blue text)
* "Qwen2.5-Math-1.5B-instruct Process:" (in blue text)
* **Connecting Annotations:**
* Between the first and second panel: A double-headed arrow labeled "Model Type Difference".
* Between the second and third panel: A double-headed arrow labeled "Model Size Difference".
* **Footer Summary Boxes (Yellow background, bottom of each panel):**
* **Left (ChatGPT-4o):** "Chain Length: 6 steps", "Solution Style: Analyze, Calculate", "Answer: 56"
* **Center (Qwen2.5-Math-72B-instruct):** "Chain Length: 10 steps", "Solution Style: Solve Equations", "Answer: 57"
* **Right (Qwen2.5-Math-1.5B-instruct):** "Chain Length: 3 steps", "Solution Style: Enumerate", "Answer: 56"
* **Logos:** Each panel contains a small logo in its bottom-right corner (OpenAI logo for ChatGPT-4o, Qwen logo for the other two).
### Detailed Analysis
**1. ChatGPT-4o Process (Left Panel):**
* **Methodology:** Begins by denoting the five numbers as `a,b,c,d,e` with `a<b<c<d<e`.
* **Step 1:** Calculates the sum of all pairwise sums. It states the total is `4(a+b+c+d+e)` and defines `S = a+b+c+d+e`, concluding the total sum is `4S`.
* **Step 2:** Calculates the sum of the given pairwise sums (101 through 111, excluding 110). It states the total is 1066, leading to the equation `4S=1066`, so `S=266.5`.
* **Process End:** The text ends with "..." indicating omitted steps before the final answer.
* **Summary:** Chain Length: 6 steps. Solution Style: Analyze, Calculate. Final Answer: **56**.
**2. Qwen2.5-Math-72B-instruct Process (Center Panel):**
* **Methodology:** Also starts by denoting the numbers as `a,b,c,d,e` with `a<b<c<d<e`.
* **Step 1:** Identifies specific pairwise sums: `a+b=101` (smallest), `d+e=111` (largest), `a+c=102`, `c+e=109`, `a+d=103`, `b+e=108`.
* **Step 2:** Proposes solving these equations step-by-step. It shows the first subtraction: `(a+c)-(a+b)=102-101` leading to `c-b=1` or `c=b+1`.
* **Process End:** The text ends with "..." indicating omitted steps.
* **Summary:** Chain Length: 10 steps. Solution Style: Solve Equations. Final Answer: **57**.
**3. Qwen2.5-Math-1.5B-instruct Process (Right Panel):**
* **Methodology:** Starts by listing the given sums: "101,102,103,104,105,106,107,108,109,111".
* **Step 1:** States the goal is to identify the pair producing the highest sum.
* **Step 2:** Begins to "list all possible pairs" starting with "(101,101), (101,102), (101,103) (101,104), (101,105), (101,106)..." This approach appears to be an enumeration of combinations from the given sums, which is a different strategy.
* **Process End:** The text ends with "..." indicating omitted steps.
* **Summary:** Chain Length: 3 steps. Solution Style: Enumerate. Final Answer: **56**.
### Key Observations
1. **Divergent Answers:** The most significant observation is the discrepancy in the final answer. The 72B-parameter model concludes the largest number is **57**, while both ChatGPT-4o and the smaller 1.5B model conclude it is **56**.
2. **Contrasting Methodologies:**
* **ChatGPT-4o** uses an **analytical/calculative** approach, focusing on the total sum of all pairs.
* **Qwen2.5-Math-72B** uses an **algebraic equation-solving** approach, setting up and manipulating specific equations derived from the smallest and largest sums.
* **Qwen2.5-Math-1.5B** uses an **enumerative** approach, attempting to list pairs directly from the given sums.
3. **Chain Length vs. Model Size:** The largest model (72B) has the longest described chain (10 steps), while the smallest model (1.5B) has the shortest (3 steps). ChatGPT-4o is intermediate (6 steps). This suggests a correlation between model size/capability and the complexity of the reasoning chain it generates for this problem.
4. **Spatial Layout:** The diagram uses a left-to-right flow to compare models. The "Model Type Difference" arrow contrasts the proprietary model (ChatGPT-4o) with the open-weight Qwen models. The "Model Size Difference" arrow contrasts the two Qwen models of different scales (72B vs. 1.5B parameters).
### Interpretation
This diagram serves as a case study in **AI model reasoning divergence**. It demonstrates that different AI architectures, training paradigms, and model sizes can lead to fundamentally different problem-solving strategies for the same logical puzzle, even resulting in different final answers.
* **What the Data Suggests:** The core mathematical problem has a single correct answer. The fact that two models agree on 56 and one (the largest) disagrees with 57 creates an investigative scenario. One must verify the correct solution to determine which model's reasoning is flawed. The 72B model's algebraic setup appears more rigorous at first glance, but its answer differs. This highlights the challenge of evaluating AI reasoning without a ground truth.
* **Relationship Between Elements:** The connecting arrows frame the comparison. The "Type Difference" suggests that the fundamental design of ChatGPT versus Qwen influences their approach. The "Size Difference" within the Qwen family isolates the effect of scale, showing that a larger model (72B) adopts a more complex, equation-based method compared to the smaller model's (1.5B) simplistic enumeration.
* **Notable Anomalies:** The primary anomaly is the answer split. A secondary observation is that the enumerative approach of the 1.5B model, while short, is likely incorrect or incomplete for this problem type, as it seems to be enumerating pairs *from the sum list* rather than deducing the original numbers. The diagram effectively exposes how model "confidence" (implied by a detailed chain) does not guarantee correctness, and how different "solution styles" are employed as heuristics.
DECODING INTELLIGENCE...