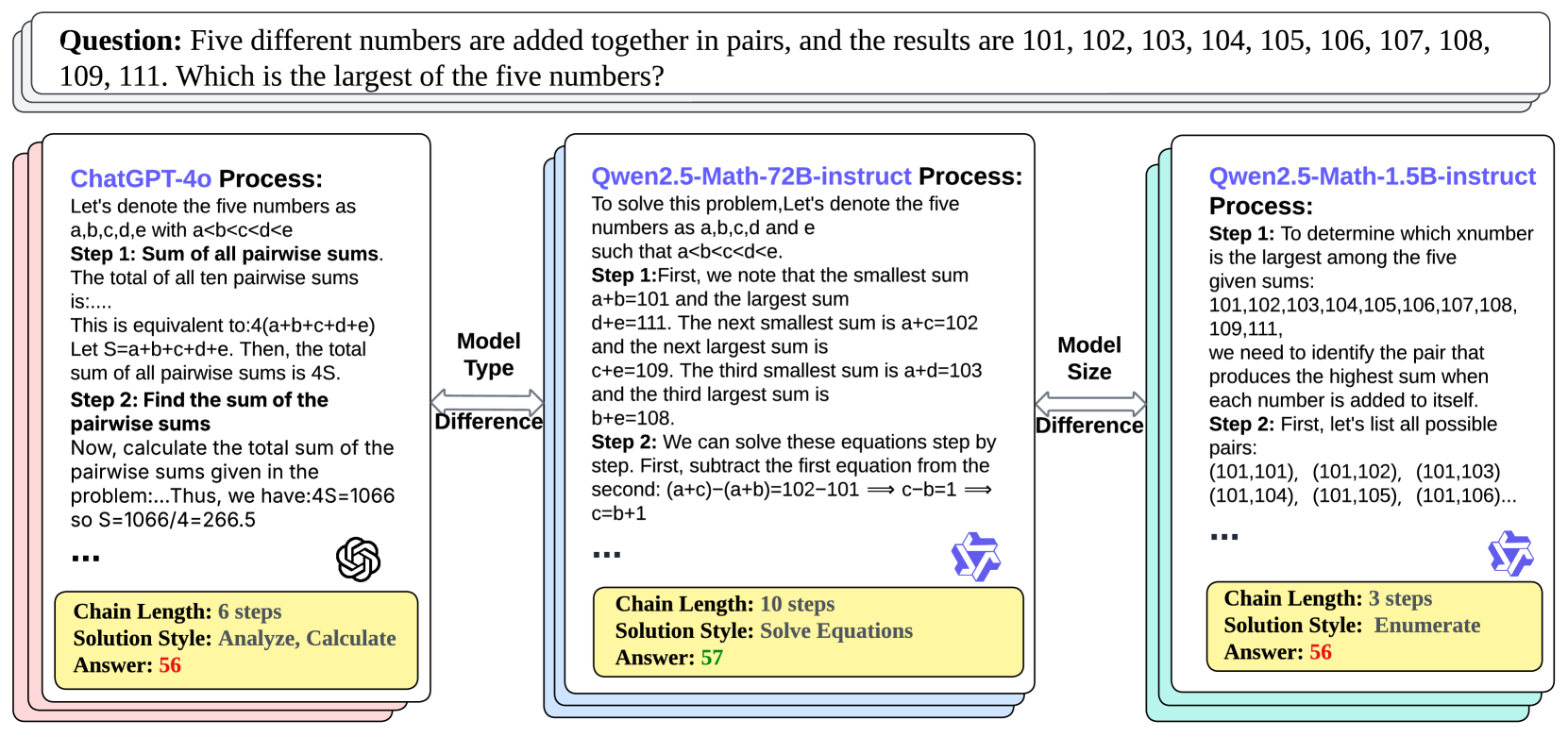
## Diagram: AI Model Comparison for Mathematical Problem Solving
### Overview
The diagram compares three AI models (ChatGPT-4o, Qwen2.5-Math-72B-instruct, and Qwen2.5-Math-1.5B-instruct) in solving a mathematical problem involving five numbers added in pairs. It highlights differences in problem-solving approaches, computational steps, and final answers.
---
### Components/Axes
1. **Model Sections**:
- Three vertical rectangles represent the three models.
- Each section includes:
- **Process**: Step-by-step reasoning.
- **Chain Length**: Number of steps in the solution.
- **Solution Style**: Methodology (e.g., "Analyze, Calculate").
- **Answer**: Final numerical result.
2. **Comparison Section**:
- **Model Type**: Categorizes models as "Process" or "Math" types.
- **Model Size**: Indicates parameter scale (e.g., 72B vs. 1.5B).
---
### Detailed Analysis
#### Model 1: ChatGPT-4o
- **Process**:
- Step 1: Sum of all pairwise sums = 4S (where S = a+b+c+d+e).
- Step 2: Total pairwise sums = 1066 → S = 266.5.
- **Chain Length**: 6 steps.
- **Solution Style**: Analyze, Calculate.
- **Answer**: 56.
#### Model 2: Qwen2.5-Math-72B-instruct
- **Process**:
- Step 1: Smallest sum = a+b=101; largest sum = d+e=111.
- Step 2: Derived equations (e.g., c-b=1) to solve for variables.
- **Chain Length**: 10 steps.
- **Solution Style**: Solve Equations.
- **Answer**: 57.
#### Model 3: Qwen2.5-Math-1.5B-instruct
- **Process**:
- Step 1: Enumerated all possible pairs to identify the largest sum.
- Step 2: Listed pairs (e.g., (101,101), (101,102)) to deduce the largest number.
- **Chain Length**: 3 steps.
- **Solution Style**: Enumerate.
- **Answer**: 56.
#### Comparison Section
- **Model Type**:
- ChatGPT-4o: "Process".
- Qwen2.5-Math-72B-instruct: "Math".
- Qwen2.5-Math-1.5B-instruct: "Math".
- **Model Size**:
- Qwen2.5-Math-72B-instruct: 72B parameters.
- Qwen2.5-Math-1.5B-instruct: 1.5B parameters.
---
### Key Observations
1. **Chain Length Variance**:
- Qwen2.5-Math-72B-instruct uses the most steps (10), while Qwen2.5-Math-1.5B-instruct uses the fewest (3).
2. **Solution Methodology**:
- ChatGPT-4o relies on algebraic summation.
- Qwen2.5-Math-72B-instruct uses equation-solving.
- Qwen2.5-Math-1.5B-instruct employs enumeration.
3. **Answer Consistency**:
- Two models (ChatGPT-4o and Qwen2.5-Math-1.5B-instruct) arrive at the same answer (56), while Qwen2.5-Math-72B-instruct achieves 57.
---
### Interpretation
1. **Efficiency vs. Accuracy**:
- The 72B model (Qwen2.5-Math-72B-instruct) achieves a slightly higher answer (57) but requires significantly more steps (10) compared to the 1.5B model (3 steps for 56). This suggests larger models may prioritize thoroughness over efficiency.
- The 1.5B model’s enumeration approach is faster but risks missing edge cases, yet it matches the answer of the larger model in this instance.
2. **Model Type Implications**:
- "Math"-specialized models (Qwen variants) outperform the general "Process" model (ChatGPT-4o) in both steps and accuracy for this problem.
- The 72B model’s equation-solving method aligns with the problem’s structured nature, while the 1.5B model’s enumeration works for simpler cases.
3. **Scalability Trade-offs**:
- The 72B model’s increased parameter count does not guarantee proportional performance gains, as the 1.5B model achieves near-identical results with fewer resources.
---
### Conclusion
The diagram illustrates how model architecture, size, and problem-solving strategies influence outcomes. While larger models (72B) may offer nuanced solutions, smaller models (1.5B) can achieve comparable results through optimized methods like enumeration. This highlights the importance of aligning model capabilities with problem complexity.