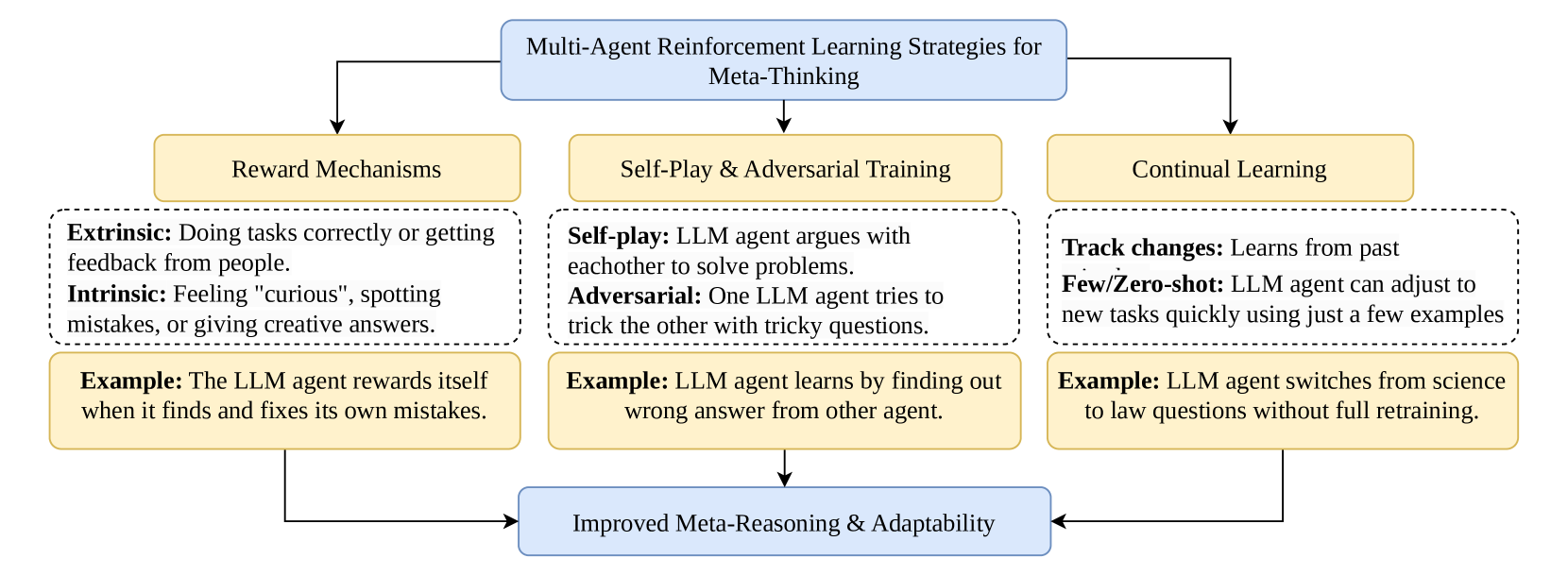
# Multi-Agent Reinforcement Learning Strategies for Meta-Thinking
## Overview
This diagram illustrates a framework for enhancing meta-reasoning and adaptability in Large Language Models (LLMs) through three core strategies: **Reward Mechanisms**, **Self-Play & Adversarial Training**, and **Continual Learning**. Each strategy contributes to improved agent performance via distinct mechanisms.
---
## 1. Reward Mechanisms
### Labels & Descriptions
- **Extrinsic**
- **Description**: Rewards for correct task completion or feedback from external sources (e.g., human input).
- **Intrinsic**
- **Description**: Internal motivations such as curiosity, error detection, or creative problem-solving.
### Example
- **Example**: An LLM agent rewards itself when it identifies and corrects its own mistakes.
---
## 2. Self-Play & Adversarial Training
### Labels & Descriptions
- **Self-play**
- **Description**: LLMs collaborate to solve problems through iterative interaction.
- **Adversarial**
- **Description**: LLMs challenge each other with deceptive or complex questions to improve robustness.
### Example
- **Example**: An LLM learns by identifying incorrect answers generated by another agent.
---
## 3. Continual Learning
### Labels & Descriptions
- **Track changes**
- **Description**: Agents learn from historical data to adapt to evolving environments.
- **Few/Zero-shot**
- **Description**: LLMs generalize to new tasks with minimal or no additional training examples.
### Example
- **Example**: An LLM transitions from science to law questions without full retraining.
---
## Outcomes
All three strategies converge to enable **Improved Meta-Reasoning & Adaptability**, allowing LLMs to:
1. Reflect on and refine their decision-making processes.
2. Generalize across diverse domains and tasks.
3. Adapt dynamically to novel challenges with limited data.
---
## Diagram Flow
1. **Reward Mechanisms** → **Improved Meta-Reasoning**
2. **Self-Play & Adversarial Training** → **Improved Meta-Reasoning**
3. **Continual Learning** → **Improved Meta-Reasoning**
All pathways feed into the final outcome of enhanced adaptability and reasoning capabilities.
---
### Key Trends & Data Points
- **Extrinsic vs. Intrinsic Rewards**: Combines external validation with internal motivation for holistic learning.
- **Self-Play**: Emphasizes collaborative problem-solving.
- **Adversarial Training**: Focuses on stress-testing agents to improve resilience.
- **Continual Learning**: Highlights efficiency in adapting to new tasks with minimal data.
This framework underscores the synergy between reinforcement learning strategies and meta-cognitive development in LLMs.