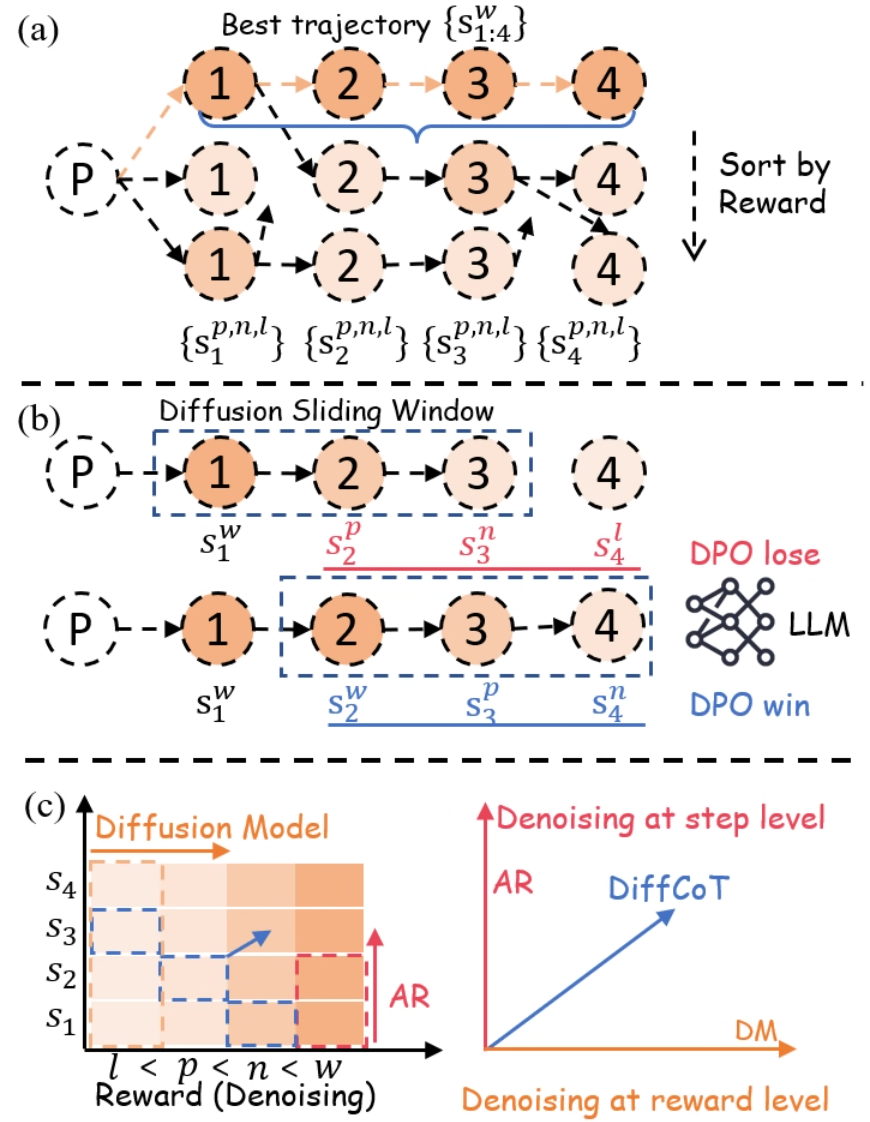
## Diagram: Multi-Stage Decision and Diffusion Model Architecture
### Overview
The image presents a technical diagram illustrating a multi-stage decision-making process combined with a diffusion model. It is divided into three sections:
1. **Best Trajectory Selection** (a)
2. **Diffusion Sliding Window** (b)
3. **Diffusion Model Heatmap** (c)
### Components/Axes
#### (a) Best Trajectory Selection
- **Nodes**: Labeled 1–4, with subscripts indicating state variations (e.g., {s₁₁₄}, {s₂₁₄}, etc.).
- **Arrows**: Directed from a central node labeled "P" to nodes 1–4, with a highlighted "Best trajectory" path (blue line) connecting nodes 1→2→3→4.
- **Sorting**: A dashed arrow labeled "Sort by Reward" points downward from node 4.
- **Subscripts**: Nodes are annotated with subscripts like {s₁₁₄}, {s₂₁₄}, {s₃₁₄}, {s₄₁₄}, suggesting hierarchical or contextual state definitions.
#### (b) Diffusion Sliding Window
- **Nodes**: Labeled 1–4, with subscripts {s₁₁₄}, {s₂₁₄}, {s₃₁₄}, {s₄₁₄}.
- **Sliding Window**: A blue dashed box highlights nodes 1→2→3, labeled "Diffusion Sliding Window."
- **DPO Outcomes**:
- **DPO lose**: Red arrow pointing to a network labeled "LLM" (Large Language Model).
- **DPO win**: Blue arrow pointing to a network labeled "DPO win."
- **Legend**: Located on the right, with red for "DPO lose" and blue for "DPO win."
#### (c) Diffusion Model Heatmap
- **Axes**:
- **X-axis**: "Reward (Denoising)" with labels l < p < n < w.
- **Y-axis**: "S₁" to "S₄" (states).
- **Heatmap**: Gradient from light orange (low reward) to dark orange (high reward).
- **Arrows**:
- **AR (Adaptive Reward)**: Red arrow pointing upward from the heatmap.
- **DiffCoT (Diffusion CoT)**: Blue arrow pointing upward from the heatmap.
- **Denoising Arrows**:
- **Step-level denoising**: Orange arrow labeled "Denoising at step level."
- **Reward-level denoising**: Blue arrow labeled "Denoising at reward level."
### Detailed Analysis
#### (a) Best Trajectory Selection
- The "Best trajectory" (blue line) connects nodes 1→2→3→4, indicating an optimal path.
- Nodes are annotated with subscripts (e.g., {s₁₁₄}), suggesting state-specific parameters or constraints.
- The "Sort by Reward" instruction implies a post-processing step to prioritize trajectories based on reward metrics.
#### (b) Diffusion Sliding Window
- The sliding window (blue box) spans nodes 1→2→3, emphasizing sequential state transitions.
- **DPO lose** (red) and **DPO win** (blue) outcomes are tied to the LLM and DPO win networks, respectively.
- The legend confirms color coding: red for negative outcomes (DPO lose) and blue for positive outcomes (DPO win).
#### (c) Diffusion Model Heatmap
- The heatmap visualizes the relationship between reward (denoising) and states (S₁–S₄).
- **AR** and **DiffCoT** arrows suggest mechanisms to adjust reward or denoising strategies.
- The gradient indicates that higher rewards (darker orange) correlate with specific states (e.g., S₄).
### Key Observations
1. **Best Trajectory**: The highlighted path (1→2→3→4) is the optimal sequence, prioritized by reward.
2. **Sliding Window Dynamics**: The diffusion process evaluates sequential states (1→2→3) to determine outcomes (DPO lose/win).
3. **Heatmap Trends**: The gradient and arrows suggest that denoising strategies (AR, DiffCoT) influence reward outcomes, with step-level denoising affecting intermediate states and reward-level denoising impacting final rewards.
### Interpretation
- The diagram illustrates a **reinforcement learning framework** where decisions (nodes 1–4) are optimized via reward-based sorting.
- The **diffusion sliding window** acts as a mechanism to evaluate sequential state transitions, with DPO outcomes (lose/win) determining the model's adaptability.
- The **heatmap** quantifies the relationship between denoising steps and rewards, showing that higher rewards (S₄) are associated with specific denoising strategies (AR, DiffCoT).
- **DPO lose/win** outcomes are critical for refining the model, as they directly influence the LLM's performance.
- The **step-level vs. reward-level denoising** arrows imply a hierarchical approach: step-level adjustments optimize intermediate states, while reward-level adjustments target final outcomes.
This architecture likely supports a **reinforcement learning with diffusion-based exploration**, where the model balances exploration (diffusion) and exploitation (reward optimization) to identify optimal trajectories.