\n
## Screenshot: Reinforcement Learning Environment
### Overview
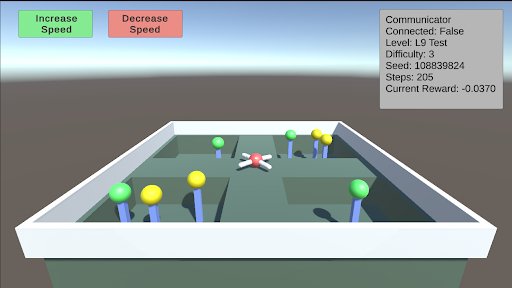
The image depicts a screenshot of a 3D reinforcement learning environment. It appears to be a simulated arena with obstacles and a central agent. The top-left corner shows controls for adjusting the simulation speed, and the top-right corner displays simulation parameters. The environment itself is a grid-like structure with colored cylinders representing obstacles or targets.
### Components/Axes
The screenshot contains the following elements:
* **Top-Left Controls:**
* "Increase Speed" button (Green)
* "Decrease Speed" button (Red)
* **Top-Right Parameters:**
* "Communicator" : False
* "Connected" : False
* "Level" : L9 Test
* "Difficulty" : 3
* "Seed" : 108839824
* "Steps" : 205
* "Current Reward" : -0.0370
* **Environment:** A square arena with a grid pattern.
* Green Cylinders: Scattered throughout the arena. Approximately 10 visible.
* Yellow Cylinders: Scattered throughout the arena. Approximately 6 visible.
* Blue Cylinders: Scattered throughout the arena. Approximately 4 visible.
* Red and White Agent: Located near the center of the arena.
### Detailed Analysis or Content Details
The simulation parameters provide quantitative information about the current state of the environment:
* **Communicator:** False - Indicates no external communication is active.
* **Connected:** False - Indicates the simulation is not connected to a network or external system.
* **Level:** L9 Test - Specifies the current level of the simulation, labeled as a "Test" level.
* **Difficulty:** 3 - Represents the difficulty setting of the simulation.
* **Seed:** 108839824 - A random seed used for initializing the simulation, ensuring reproducibility.
* **Steps:** 205 - The number of simulation steps that have been executed.
* **Current Reward:** -0.0370 - The current reward value accumulated by the agent. This is a negative value, suggesting the agent is not performing optimally.
The environment consists of a grid with three types of cylindrical obstacles/targets: green, yellow, and blue. The agent, represented by a red and white object, is positioned near the center of the grid. The agent's position appears to be slightly offset from the exact center.
### Key Observations
* The negative current reward suggests the agent is facing challenges in achieving its goal within the environment.
* The simulation is in a "Test" level, indicating it might be used for evaluating the agent's performance.
* The seed value allows for recreating the exact same simulation conditions.
* The environment is relatively sparse, with obstacles/targets distributed across the grid.
### Interpretation
This screenshot represents a reinforcement learning environment designed for training an agent to navigate and interact with its surroundings. The agent's goal is likely to collect rewards by interacting with the environment, potentially by reaching specific targets (the colored cylinders) or avoiding obstacles. The negative current reward indicates that the agent is currently not performing well, and further training is required. The parameters like level, difficulty, and seed provide control and reproducibility for the training process. The visual representation of the environment allows for a qualitative assessment of the agent's behavior and the challenges it faces. The lack of a "Communicator" and "Connected" status suggests this is a standalone simulation, not part of a distributed or networked learning system. The "L9 Test" level suggests this is a specific test case designed to evaluate the agent's performance at a particular stage of training.