\n
## Diagram: Variational Autoencoder (VAE) with Attention Mechanism
### Overview
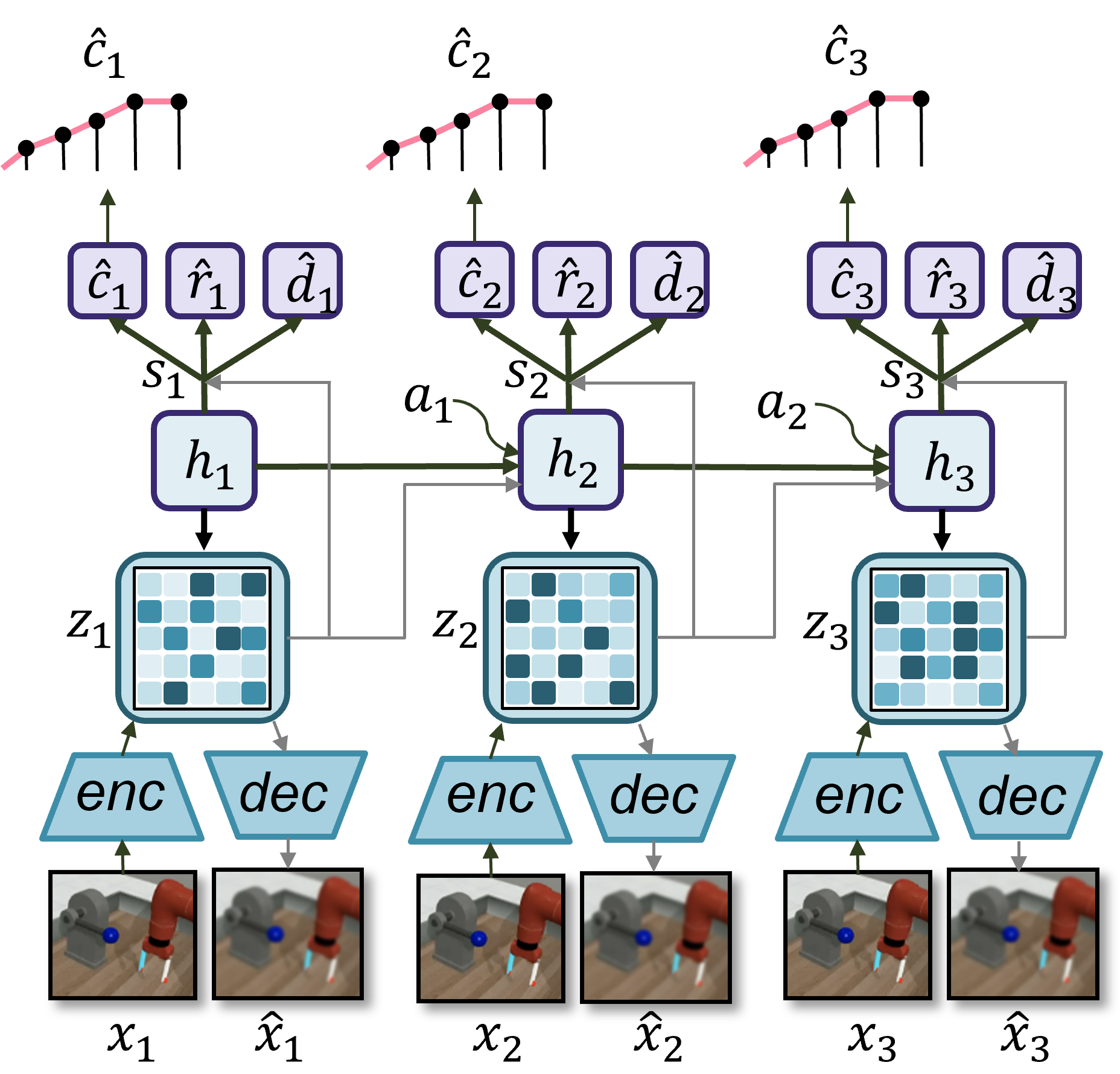
The image depicts a diagram of a Variational Autoencoder (VAE) architecture with an attention mechanism applied across three sequential time steps. The diagram illustrates the encoding, latent space representation, decoding, and attention processes involved in the model. It appears to be modeling a sequence of images of a robotic arm.
### Components/Axes
The diagram consists of three identical blocks representing sequential time steps (1, 2, and 3). Each block contains the following components:
* **Input Images:** `x1`, `x2`, `x3` (original images) and `x̂1`, `x̂2`, `x̂3` (reconstructed images).
* **Encoder (enc):** Transforms the input image into a latent representation.
* **Latent Space (z1, z2, z3):** A grid-like representation of the latent variables.
* **Decoder (dec):** Reconstructs the image from the latent representation.
* **Hidden State (h1, h2, h3):** Represents the hidden state of the recurrent network.
* **Context Vector (ĉ1, ĉ2, ĉ3):** Represents the context vector.
* **Reward (r̂1, r̂2, r̂3):** Represents the reward.
* **Decision (d̂1, d̂2, d̂3):** Represents the decision.
* **Attention Weights (a1, a2):** Connect the hidden states and context vectors across time steps.
* **State Transition (s1, s2, s3):** Connects the hidden states across time steps.
### Detailed Analysis or Content Details
The diagram shows a sequential VAE model with three time steps.
**Time Step 1:**
* Input image: `x1`
* Reconstructed image: `x̂1`
* Latent variable: `z1` (represented as a 8x8 grid with varying shades of blue)
* Hidden state: `h1`
* Context vector: `ĉ1`
* Reward: `r̂1`
* Decision: `d̂1`
**Time Step 2:**
* Input image: `x2`
* Reconstructed image: `x̂2`
* Latent variable: `z2` (represented as a 8x8 grid with varying shades of blue)
* Hidden state: `h2`
* Context vector: `ĉ2`
* Reward: `r̂2`
* Decision: `d̂2`
* Attention weight: `a1` (connecting `h1` to `ĉ2`)
**Time Step 3:**
* Input image: `x3`
* Reconstructed image: `x̂3`
* Latent variable: `z3` (represented as a 8x8 grid with varying shades of blue)
* Hidden state: `h3`
* Context vector: `ĉ3`
* Reward: `r̂3`
* Decision: `d̂3`
* Attention weight: `a2` (connecting `h2` to `ĉ3`)
The attention mechanism is implemented by connecting the hidden states of previous time steps to the context vectors of subsequent time steps using attention weights `a1` and `a2`. The state transition `s1` connects `h1` to `h2`, and `s2` connects `h2` to `h3`.
The images show a robotic arm manipulating a block. The reconstructed images `x̂1`, `x̂2`, and `x̂3` appear visually similar to the original images `x1`, `x2`, and `x3`, suggesting the decoder is effectively reconstructing the input.
### Key Observations
* The model utilizes a recurrent structure to process sequential data.
* The attention mechanism allows the model to focus on relevant information from previous time steps.
* The latent space provides a compressed representation of the input data.
* The model predicts a reward and decision at each time step.
* The latent space `z` appears to be a 8x8 grid, with varying intensity of blue.
### Interpretation
This diagram illustrates a sophisticated VAE architecture designed for sequential data modeling, specifically for tasks involving robotic manipulation. The attention mechanism is crucial for enabling the model to maintain context and make informed decisions over time. The VAE component allows the model to learn a compressed, latent representation of the observed states, which can be used for planning and control. The prediction of reward and decision suggests the model is being trained to optimize a specific task, such as successfully manipulating the block. The sequential nature of the model, combined with the attention mechanism, suggests it is capable of handling complex, temporally-dependent tasks. The fact that the reconstructed images are similar to the original images indicates that the model is learning a meaningful representation of the input data. The model is likely being used for reinforcement learning or imitation learning, where the reward signal guides the learning process. The attention mechanism allows the model to focus on the most relevant parts of the past sequence when making decisions.