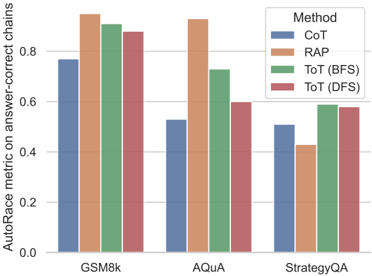
## Bar Chart: AutoRace Metric Comparison Across Methods and Datasets
### Overview
The chart compares the performance of four reasoning methods (CoT, RAP, ToT-BFS, ToT-DFS) across three question-answering datasets (GSM8k, AQuA, StrategyQA) using the AutoRace metric, which measures the proportion of answer-correct chains. The y-axis ranges from 0.0 to 0.8, and the x-axis lists datasets with grouped bars for each method.
### Components/Axes
- **X-axis**: Datasets (GSM8k, AQuA, StrategyQA), each with four bars representing methods.
- **Y-axis**: AutoRace metric (0.0–0.8), labeled "AutoRace metric on answer-correct chains."
- **Legend**: Located in the top-right corner, mapping colors to methods:
- Blue: CoT
- Orange: RAP
- Green: ToT (BFS)
- Red: ToT (DFS)
### Detailed Analysis
#### GSM8k Dataset
- **CoT (Blue)**: ~0.75
- **RAP (Orange)**: ~0.9 (tallest bar)
- **ToT (BFS) (Green)**: ~0.85
- **ToT (DFS) (Red)**: ~0.8
#### AQuA Dataset
- **CoT (Blue)**: ~0.5
- **RAP (Orange)**: ~0.9
- **ToT (BFS) (Green)**: ~0.7
- **ToT (DFS) (Red)**: ~0.6
#### StrategyQA Dataset
- **CoT (Blue)**: ~0.5
- **RAP (Orange)**: ~0.4 (shortest bar)
- **ToT (BFS) (Green)**: ~0.6
- **ToT (DFS) (Red)**: ~0.6
### Key Observations
1. **RAP Dominates in GSM8k and AQuA**: RAP achieves the highest scores in both GSM8k (~0.9) and AQuA (~0.9), outperforming other methods.
2. **RAP Underperforms in StrategyQA**: RAP drops to ~0.4 in StrategyQA, while ToT methods (BFS/DFS) maintain ~0.6.
3. **ToT Consistency**: ToT-BFS and ToT-DFS show similar performance across datasets, with slight variations (e.g., ToT-BFS edges out ToT-DFS in GSM8k and AQuA).
4. **CoT Variability**: CoT performs moderately in GSM8k (~0.75) but lags in AQuA (~0.5) and StrategyQA (~0.5).
### Interpretation
The AutoRace metric highlights method-specific strengths:
- **RAP** excels in structured reasoning tasks (GSM8k, AQuA) but struggles with complex, multi-step problems (StrategyQA), suggesting potential limitations in handling ambiguity or depth.
- **ToT (BFS/DFS)** demonstrates robustness across datasets, with BFS slightly outperforming DFS in simpler tasks. Their consistent ~0.6 score in StrategyQA indicates better adaptability to complex reasoning.
- **CoT** underperforms relative to other methods, possibly due to its reliance on static chain generation without iterative refinement.
The data implies that method effectiveness is dataset-dependent, with RAP favoring simpler tasks and ToT methods handling complexity more effectively. Further analysis could explore why RAP falters in StrategyQA, potentially revealing architectural or heuristic limitations.