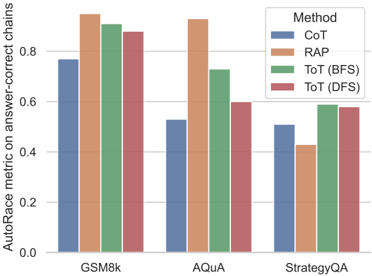
## Bar Chart: AutoRace Metric Comparison
### Overview
The image is a bar chart comparing the performance of different methods (CoT, RAP, ToT (BFS), ToT (DFS)) on three datasets (GSM8k, AQuA, StrategyQA) using the AutoRace metric on answer-correct chains. The chart displays the metric values for each method on each dataset, allowing for a direct comparison of their effectiveness.
### Components/Axes
* **Y-axis:** "AutoRace metric on answer-correct chains". The scale ranges from 0.0 to 0.8, with increments of 0.2.
* **X-axis:** Datasets: GSM8k, AQuA, StrategyQA.
* **Legend:** Located at the top-right of the chart.
* CoT (Chain-of-Thought): Blue
* RAP (Retrieval-Augmented Prompting): Orange
* ToT (BFS) (Tree of Thoughts, Breadth-First Search): Green
* ToT (DFS) (Tree of Thoughts, Depth-First Search): Red
### Detailed Analysis
**GSM8k Dataset:**
* CoT (Blue): Approximately 0.77
* RAP (Orange): Approximately 0.92
* ToT (BFS) (Green): Approximately 0.90
* ToT (DFS) (Red): Approximately 0.88
**AQuA Dataset:**
* CoT (Blue): Approximately 0.53
* RAP (Orange): Approximately 0.91
* ToT (BFS) (Green): Approximately 0.70
* ToT (DFS) (Red): Approximately 0.90
**StrategyQA Dataset:**
* CoT (Blue): Approximately 0.51
* RAP (Orange): Approximately 0.43
* ToT (BFS) (Green): Approximately 0.59
* ToT (DFS) (Red): Approximately 0.58
### Key Observations
* RAP consistently performs well across all datasets, often achieving the highest AutoRace metric.
* CoT generally has the lowest performance compared to the other methods.
* The performance of ToT (BFS) and ToT (DFS) is relatively similar within each dataset.
* The performance variance across datasets is significant for all methods.
### Interpretation
The bar chart provides a comparative analysis of different methods for improving the accuracy of answer chains. The AutoRace metric on answer-correct chains serves as the evaluation criterion.
* **RAP's Superiority:** The consistently high performance of RAP suggests that retrieval-augmented prompting is an effective strategy for enhancing the quality of answer chains across various datasets.
* **CoT's Limitations:** The lower performance of CoT indicates that simply generating chains of thought may not be sufficient for achieving high accuracy, especially when compared to methods that incorporate retrieval or tree-based search.
* **ToT's Effectiveness:** The performance of ToT (BFS) and ToT (DFS) demonstrates the potential of tree-based search strategies for improving answer chain accuracy. The similarity in performance between BFS and DFS suggests that the search strategy may not be as critical as the overall tree-of-thoughts approach.
* **Dataset Dependency:** The significant performance variance across datasets highlights the importance of considering the specific characteristics of each dataset when evaluating and comparing different methods. Some methods may be more suitable for certain types of questions or reasoning tasks.
In summary, the data suggests that retrieval-augmented prompting (RAP) is a particularly effective strategy for improving the accuracy of answer chains, while simple chain-of-thought generation (CoT) may be less effective. Tree-of-thoughts approaches (ToT) also show promise, and the choice of search strategy (BFS vs. DFS) may not be as critical as the overall tree-based approach. The performance of each method is also highly dependent on the specific dataset being used.