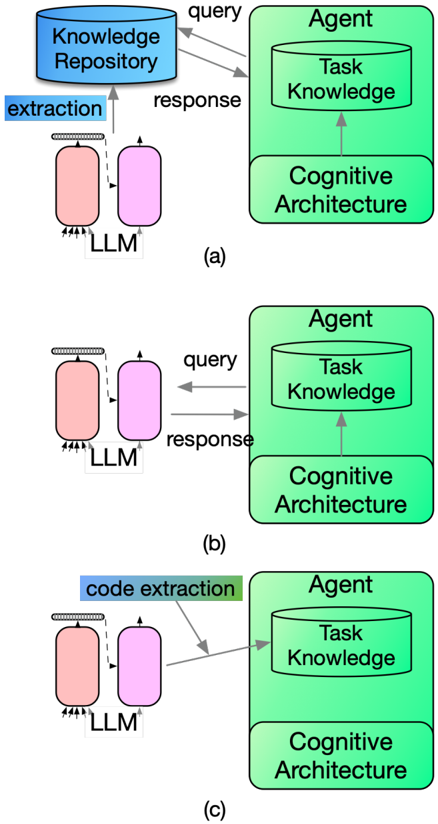
## Diagram: LLM Interaction with Knowledge Repository and Agent
### Overview
The image presents three diagrams (a, b, c) illustrating different modes of interaction between a Large Language Model (LLM), a Knowledge Repository, and an Agent with a Cognitive Architecture. Each diagram shows a slightly different configuration of information flow.
### Components/Axes
* **Knowledge Repository:** A blue cylinder labeled "Knowledge Repository."
* **Agent:** A green rounded rectangle containing "Task Knowledge" (represented as a cylinder) and "Cognitive Architecture" (a smaller rounded rectangle below the Task Knowledge).
* **LLM:** Two rounded rectangles, one pink and one red, labeled "LLM." The red rectangle has small arrows pointing into it from the bottom.
* **Arrows:** Represent the flow of information, labeled as "query" and "response," or "extraction" and "code extraction."
### Detailed Analysis
**Diagram (a):**
* The Knowledge Repository sends a "query" to the Agent and receives a "response" from the Agent.
* The red LLM receives input (indicated by small arrows) and performs "extraction," sending the extracted information to the Knowledge Repository.
* The pink LLM sends output to the Agent.
**Diagram (b):**
* The Agent sends a "query" to the pink LLM and receives a "response" from it.
* The red LLM receives input (indicated by small arrows) and sends output to the pink LLM.
**Diagram (c):**
* The red LLM receives input (indicated by small arrows) and performs "code extraction," sending the extracted code to the Agent.
* The pink LLM sends output to the Agent.
### Key Observations
* The LLM's role varies across the three diagrams, acting as an extractor of information for the Knowledge Repository (a), as an intermediary between the Agent and external input (b), and as a code extractor for the Agent (c).
* The Agent consistently interacts with the LLM, either receiving information or sending queries.
* The Knowledge Repository only interacts directly with the LLM in diagram (a).
### Interpretation
The diagrams illustrate different ways an LLM can be integrated into a system involving a Knowledge Repository and an Agent. Diagram (a) shows the LLM as a data extraction tool, enriching the Knowledge Repository. Diagram (b) shows the LLM as a component that facilitates communication between the Agent and external data. Diagram (c) shows the LLM as a code extraction tool, providing the Agent with executable code. The diagrams highlight the versatility of LLMs and their potential to enhance various aspects of intelligent systems. The choice of architecture depends on the specific task and the desired interaction between the components.