\n
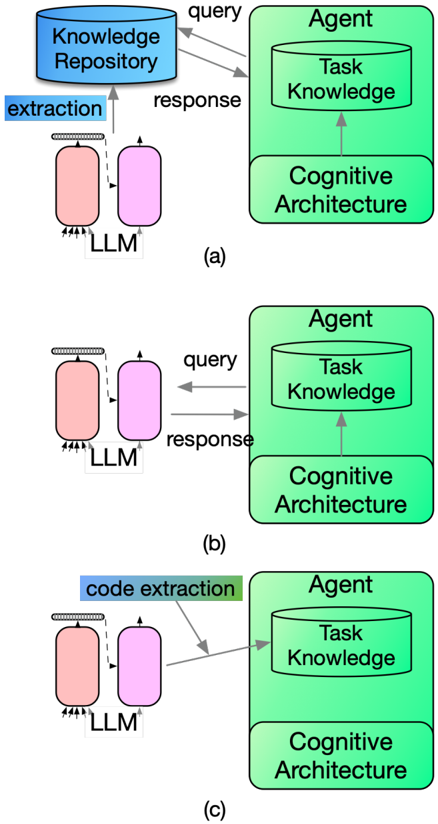
## Diagram: LLM-Agent Interaction Scenarios
### Overview
The image presents a series of three diagrams (labeled a, b, and c) illustrating different interaction scenarios between a Large Language Model (LLM) and an Agent. Each diagram depicts the flow of information – queries and responses – between the LLM and the Agent, with varying focuses on the type of extraction performed. The diagrams are vertically stacked.
### Components/Axes
Each diagram consists of two main components:
* **LLM (Large Language Model):** Represented by two connected pink rounded rectangles.
* **Agent:** Represented by a green rectangle containing two sub-components: "Task Knowledge" (yellow oval) and "Cognitive Architecture" (green rectangle).
Additionally, each diagram includes:
* **Labels:** "Knowledge Repository" (top-left), "extraction", "code extraction".
* **Arrows:** Gray arrows indicating the direction of information flow, labeled "query" and "response".
* **Diagram Identifiers:** "(a)", "(b)", and "(c)" positioned at the bottom-right of each diagram.
### Detailed Analysis or Content Details
**Diagram (a):**
* The label "extraction" is positioned above the LLM component.
* A "query" arrow originates from the Agent's "Task Knowledge" and points towards the LLM.
* A "response" arrow originates from the LLM and points towards the "Knowledge Repository".
* The "Knowledge Repository" is positioned above the LLM.
**Diagram (b):**
* No specific label is present above the LLM component.
* A "query" arrow originates from the Agent's "Task Knowledge" and points towards the LLM.
* A "response" arrow originates from the LLM and points towards the Agent's "Task Knowledge".
**Diagram (c):**
* The label "code extraction" is positioned above the LLM component.
* A "query" arrow originates from the Agent's "Task Knowledge" and points towards the LLM.
* A "response" arrow originates from the LLM and points towards the Agent's "Task Knowledge".
### Key Observations
* All three diagrams share a similar structure, highlighting the core interaction between the LLM and the Agent.
* The primary difference lies in the type of extraction being performed (general "extraction" in (a), no specific extraction in (b), and "code extraction" in (c)) and the destination of the response.
* Diagram (a) shows the LLM interacting with a "Knowledge Repository" while diagrams (b) and (c) show the LLM directly interacting with the Agent's "Task Knowledge".
### Interpretation
The diagrams illustrate different ways an LLM can be integrated into an agent-based system. The variations demonstrate how the LLM can be used for different purposes – general knowledge extraction, direct task support, or specialized code extraction – and how the resulting information is utilized within the agent's architecture.
* **Diagram (a)** suggests a scenario where the LLM is used to augment the agent's knowledge base by retrieving information from an external "Knowledge Repository".
* **Diagram (b)** represents a more direct interaction, where the LLM provides information directly to the agent's "Task Knowledge" without an intermediary repository. This could be for real-time reasoning or problem-solving.
* **Diagram (c)** focuses on a specific application – code extraction – where the LLM is used to generate or analyze code, and the results are fed back into the agent's "Task Knowledge".
The consistent presence of the "Cognitive Architecture" component in the Agent suggests that it provides the overarching framework for reasoning and decision-making, regardless of the specific extraction method employed. The diagrams are conceptual and do not provide quantitative data, but rather illustrate different architectural patterns.