TECHNICAL ASSET FINGERPRINT
04dba1dc5fe0fb2b2b55511c
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
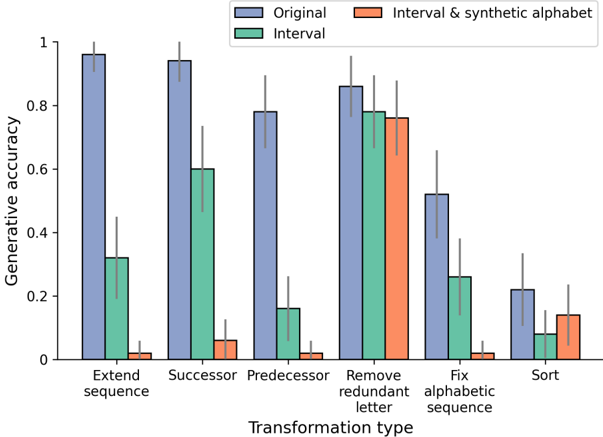
## Grouped Bar Chart: Generative Accuracy by Transformation Type
### Overview
The image displays a grouped bar chart comparing the generative accuracy of three different methods ("Original," "Interval," and "Interval & synthetic alphabet") across six distinct transformation types. The chart includes error bars for each data point, indicating variability or confidence intervals. The overall visual trend shows that the "Original" method consistently outperforms the other two methods across all tasks, with significant performance drops for the "Interval" and "Interval & synthetic alphabet" methods on most tasks.
### Components/Axes
* **Chart Type:** Grouped bar chart with error bars.
* **Y-Axis:**
* **Label:** "Generative accuracy"
* **Scale:** Linear, ranging from 0 to 1, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis:**
* **Label:** "Transformation type"
* **Categories (from left to right):**
1. Extend sequence
2. Successor
3. Predecessor
4. Remove redundant letter
5. Fix alphabetic sequence
6. Sort
* **Legend:** Located at the top center of the chart.
* **Blue Bar:** "Original"
* **Green Bar:** "Interval"
* **Orange Bar:** "Interval & synthetic alphabet"
* **Data Representation:** Each transformation type on the x-axis has a cluster of three bars (one for each method). A thin black vertical line (error bar) extends from the top of each bar.
### Detailed Analysis
**Trend Verification & Approximate Values (with uncertainty):**
* **Extend sequence:**
* *Original (Blue):* Very high accuracy, ~0.96. Error bar extends from ~0.92 to 1.0.
* *Interval (Green):* Moderate accuracy, ~0.32. Error bar extends from ~0.20 to ~0.44.
* *Interval & synthetic alphabet (Orange):* Very low accuracy, ~0.02. Error bar extends from ~0.00 to ~0.05.
* **Successor:**
* *Original (Blue):* Very high accuracy, ~0.94. Error bar extends from ~0.88 to 1.0.
* *Interval (Green):* Moderate accuracy, ~0.60. Error bar extends from ~0.46 to ~0.74.
* *Interval & synthetic alphabet (Orange):* Very low accuracy, ~0.06. Error bar extends from ~0.02 to ~0.10.
* **Predecessor:**
* *Original (Blue):* High accuracy, ~0.78. Error bar extends from ~0.66 to ~0.90.
* *Interval (Green):* Low accuracy, ~0.16. Error bar extends from ~0.08 to ~0.24.
* *Interval & synthetic alphabet (Orange):* Very low accuracy, ~0.02. Error bar extends from ~0.00 to ~0.05.
* **Remove redundant letter:**
* *Original (Blue):* High accuracy, ~0.86. Error bar extends from ~0.76 to ~0.96.
* *Interval (Green):* High accuracy, ~0.78. Error bar extends from ~0.66 to ~0.90.
* *Interval & synthetic alphabet (Orange):* High accuracy, ~0.76. Error bar extends from ~0.64 to ~0.88.
* *Note:* This is the only transformation where all three methods show comparable, high performance.
* **Fix alphabetic sequence:**
* *Original (Blue):* Moderate accuracy, ~0.52. Error bar extends from ~0.40 to ~0.64.
* *Interval (Green):* Low accuracy, ~0.26. Error bar extends from ~0.14 to ~0.38.
* *Interval & synthetic alphabet (Orange):* Very low accuracy, ~0.02. Error bar extends from ~0.00 to ~0.05.
* **Sort:**
* *Original (Blue):* Low accuracy, ~0.22. Error bar extends from ~0.10 to ~0.34.
* *Interval (Green):* Very low accuracy, ~0.08. Error bar extends from ~0.02 to ~0.14.
* *Interval & synthetic alphabet (Orange):* Very low accuracy, ~0.14. Error bar extends from ~0.06 to ~0.22.
### Key Observations
1. **Dominant Performance of "Original":** The "Original" method (blue bars) has the highest accuracy for every single transformation type.
2. **Task-Specific Performance of "Interval":** The "Interval" method (green bars) shows a wide variance in performance. It performs moderately well on "Successor" (~0.60) and very well on "Remove redundant letter" (~0.78), but poorly on "Predecessor" (~0.16) and "Sort" (~0.08).
3. **Limited Utility of "Interval & synthetic alphabet":** The combined method (orange bars) performs very poorly (accuracy < 0.10) on five out of six tasks. Its only significant performance is on "Remove redundant letter" (~0.76), where it nearly matches the other two methods.
4. **Most Difficult Task:** "Sort" appears to be the most challenging transformation for all methods, with the lowest overall accuracies.
5. **Easiest Task:** "Extend sequence" and "Successor" are the easiest tasks for the "Original" method. "Remove redundant letter" is the easiest task for the "Interval" and "Interval & synthetic alphabet" methods.
6. **Error Bars:** The error bars are generally larger for the "Interval" and "Interval & synthetic alphabet" methods, suggesting less consistent performance or higher variance in their results compared to the "Original" method.
### Interpretation
The data suggests a clear hierarchy in method effectiveness for these specific generative tasks. The "Original" method is robust and generalizes well across a variety of sequence-based transformations. The "Interval" method appears to be highly specialized; its success on "Successor" and "Remove redundant letter" implies it may be leveraging interval-based reasoning effectively for those specific operations but fails when the logic requires different reasoning (e.g., "Predecessor" or "Sort").
The most striking finding is the near-total failure of the "Interval & synthetic alphabet" method except for the "Remove redundant letter" task. This indicates that introducing a synthetic alphabet, in combination with interval reasoning, creates a model that is extremely narrowly capable. It may be over-optimized for detecting and removing redundancy within a fixed symbolic set but loses the ability to perform general sequence manipulation. This could be a case of **catastrophic specialization**, where adding a new representational component (the synthetic alphabet) destroys previously acquired general capabilities.
The chart effectively demonstrates that more complex or hybrid models (like "Interval & synthetic alphabet") are not universally better. Their utility is highly contingent on the specific problem structure, and they can perform worse than simpler baselines on most tasks. The "Remove redundant letter" task stands out as an outlier where all methods converge, suggesting its solution may be more aligned with the inductive biases of all three approaches.
DECODING INTELLIGENCE...