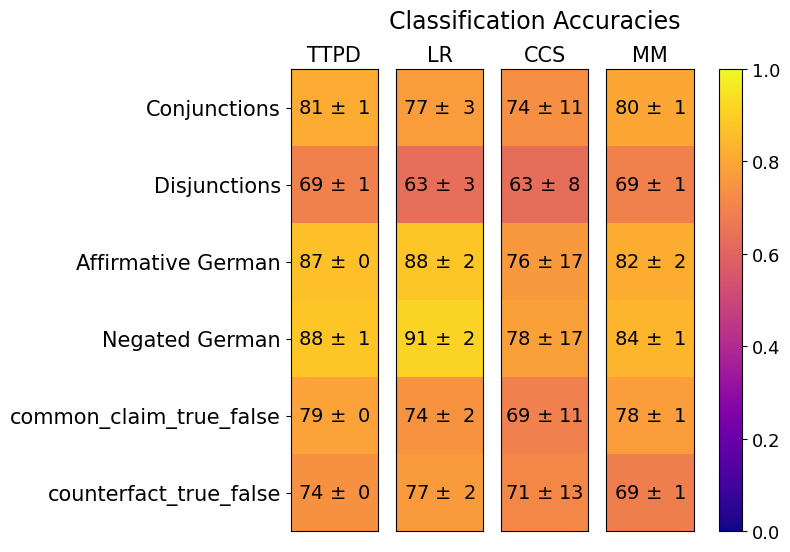
## Heatmap: Classification Accuracies
### Overview
The image is a heatmap displaying the classification accuracies of four different models (TTPD, LR, CCS, and MM) across six different categories: Conjunctions, Disjunctions, Affirmative German, Negated German, common_claim_true_false, and counterfact_true_false. The heatmap uses a color gradient from purple (0.0) to yellow (1.0) to represent the accuracy values. Each cell contains the accuracy value and its standard deviation.
### Components/Axes
* **Title:** Classification Accuracies
* **Columns (Models):** TTPD, LR, CCS, MM
* **Rows (Categories):** Conjunctions, Disjunctions, Affirmative German, Negated German, common\_claim\_true\_false, counterfact\_true\_false
* **Colorbar:** Ranges from 0.0 (purple) to 1.0 (yellow), representing the classification accuracy.
### Detailed Analysis
The heatmap presents classification accuracies for each model and category, along with the standard deviation.
* **Conjunctions:**
* TTPD: 81 ± 1
* LR: 77 ± 3
* CCS: 74 ± 11
* MM: 80 ± 1
* **Disjunctions:**
* TTPD: 69 ± 1
* LR: 63 ± 3
* CCS: 63 ± 8
* MM: 69 ± 1
* **Affirmative German:**
* TTPD: 87 ± 0
* LR: 88 ± 2
* CCS: 76 ± 17
* MM: 82 ± 2
* **Negated German:**
* TTPD: 88 ± 1
* LR: 91 ± 2
* CCS: 78 ± 17
* MM: 84 ± 1
* **common\_claim\_true\_false:**
* TTPD: 79 ± 0
* LR: 74 ± 2
* CCS: 69 ± 11
* MM: 78 ± 1
* **counterfact\_true\_false:**
* TTPD: 74 ± 0
* LR: 77 ± 2
* CCS: 71 ± 13
* MM: 69 ± 1
### Key Observations
* The LR model achieves the highest accuracy (91 ± 2) for "Negated German".
* The CCS model has the highest standard deviations across all categories, indicating greater variability in its performance.
* The "Affirmative German" and "Negated German" categories generally have higher accuracies compared to "Disjunctions" and "common\_claim\_true\_false".
* TTPD and MM models show relatively consistent performance across all categories.
### Interpretation
The heatmap provides a comparative analysis of the classification accuracies of four models across different linguistic categories. The data suggests that the LR model performs particularly well on "Negated German" tasks, while the CCS model exhibits more inconsistent performance. The higher accuracies for "Affirmative German" and "Negated German" may indicate that these categories are easier to classify compared to others. The relatively consistent performance of TTPD and MM suggests that these models are more robust across different types of linguistic tasks. The standard deviations highlight the variability in performance, with CCS showing the most significant fluctuations. This information is valuable for selecting the most appropriate model for a given task and understanding the strengths and weaknesses of each model.