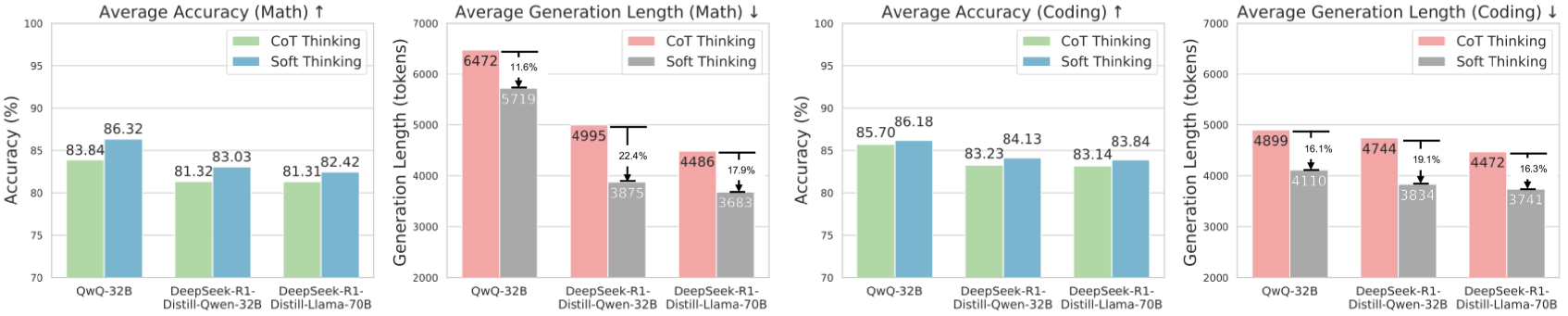
\n
## Bar Chart: Comparison of Model Performance with Chain-of-Thought (CoT) vs. Soft Thinking
### Overview
The image presents four bar charts comparing the performance of three language models – QwO-32B, DeepSeek-R1 Distill-Owen-32B, and DeepSeek-R1 Distill-Llama-70B – using two different reasoning approaches: Chain-of-Thought (CoT) Thinking and Soft Thinking. The charts evaluate performance based on Average Accuracy and Average Generation Length for both Math and Coding tasks. Each chart includes error bars representing variability.
### Components/Axes
* **X-axis:** Model Names (QwO-32B, DeepSeek-R1 Distill-Owen-32B, DeepSeek-R1 Distill-Llama-70B)
* **Y-axis (Charts 1 & 3):** Accuracy (%) - Scale ranges from 70% to 100%.
* **Y-axis (Charts 2 & 4):** Generation Length (tokens) - Scale ranges from 2000 to 7000.
* **Legend:**
* CoT Thinking (Blue)
* Soft Thinking (Red)
* **Titles:**
* "Average Accuracy (Math) ↑"
* "Average Generation Length (Math) ↓"
* "Average Accuracy (Coding) ↑"
* "Average Generation Length (Coding) ↓"
* **Error Bars:** Represent the standard error or confidence interval for each data point.
* **Percentage Labels:** Displayed above each bar indicating the accuracy or generation length.
* **Percentage Change Labels:** Displayed above the error bars, indicating the percentage difference between CoT and Soft Thinking.
### Detailed Analysis or Content Details
**Chart 1: Average Accuracy (Math) ↑**
* **QwO-32B:**
* CoT Thinking: 83.84%
* Soft Thinking: 81.32%
* **DeepSeek-R1 Distill-Owen-32B:**
* CoT Thinking: 83.03%
* Soft Thinking: 82.42%
* **DeepSeek-R1 Distill-Llama-70B:**
* CoT Thinking: 82.64%
* Soft Thinking: 81.31%
* Percentage change between CoT and Soft Thinking: approximately 2.5% for QwO-32B, 0.6% for DeepSeek-R1 Distill-Owen-32B, and 1.3% for DeepSeek-R1 Distill-Llama-70B.
**Chart 2: Average Generation Length (Math) ↓**
* **QwO-32B:**
* CoT Thinking: 6472 tokens (with ~1.18% error bar)
* Soft Thinking: 5719 tokens (with ~1.18% error bar)
* **DeepSeek-R1 Distill-Owen-32B:**
* CoT Thinking: 4995 tokens (with ~2.24% error bar)
* Soft Thinking: 3975 tokens (with ~2.24% error bar)
* **DeepSeek-R1 Distill-Llama-70B:**
* CoT Thinking: 4486 tokens (with ~1.79% error bar)
* Soft Thinking: 3603 tokens (with ~1.79% error bar)
* Percentage change between CoT and Soft Thinking: approximately 13% for QwO-32B, 25% for DeepSeek-R1 Distill-Owen-32B, and 24% for DeepSeek-R1 Distill-Llama-70B.
**Chart 3: Average Accuracy (Coding) ↑**
* **QwO-32B:**
* CoT Thinking: 86.18%
* Soft Thinking: 83.23%
* **DeepSeek-R1 Distill-Owen-32B:**
* CoT Thinking: 84.13%
* Soft Thinking: 83.14%
* **DeepSeek-R1 Distill-Llama-70B:**
* CoT Thinking: 83.84%
* Soft Thinking: 83.14%
* Percentage change between CoT and Soft Thinking: approximately 3% for QwO-32B, 1% for DeepSeek-R1 Distill-Owen-32B, and 0.7% for DeepSeek-R1 Distill-Llama-70B.
**Chart 4: Average Generation Length (Coding) ↓**
* **QwO-32B:**
* CoT Thinking: 4899 tokens (with ~1.18% error bar)
* Soft Thinking: 4110 tokens (with ~1.18% error bar)
* **DeepSeek-R1 Distill-Owen-32B:**
* CoT Thinking: 4744 tokens (with ~1.74% error bar)
* Soft Thinking: 3834 tokens (with ~1.74% error bar)
* **DeepSeek-R1 Distill-Llama-70B:**
* CoT Thinking: 4472 tokens (with ~0.73% error bar)
* Soft Thinking: 3741 tokens (with ~0.73% error bar)
* Percentage change between CoT and Soft Thinking: approximately 19% for QwO-32B, 24% for DeepSeek-R1 Distill-Owen-32B, and 16% for DeepSeek-R1 Distill-Llama-70B.
### Key Observations
* CoT Thinking consistently yields higher accuracy than Soft Thinking across all models and tasks (Math and Coding).
* CoT Thinking results in significantly longer generation lengths compared to Soft Thinking for both Math and Coding.
* The difference in generation length between CoT and Soft Thinking is more pronounced for the QwO-32B model.
* The accuracy gains from CoT Thinking are more substantial for the Coding task than for the Math task.
* The error bars suggest relatively low variability in the results.
### Interpretation
The data suggests that employing Chain-of-Thought (CoT) reasoning improves the accuracy of these language models on both Math and Coding tasks, but at the cost of increased computational resources (longer generation lengths). The consistent accuracy improvement across all models indicates that CoT is a generally effective technique. The larger generation lengths associated with CoT likely reflect the more detailed and step-by-step reasoning process it entails.
The fact that the accuracy gains are more significant for Coding suggests that CoT may be particularly beneficial for tasks requiring more complex logical reasoning. The relatively small differences in accuracy between the models themselves suggest that the reasoning approach (CoT vs. Soft Thinking) has a more substantial impact on performance than the specific model architecture, within the range tested.
The percentage change labels provide a clear quantification of the trade-off between accuracy and generation length. A decision on whether to use CoT or Soft Thinking would depend on the specific application and the relative importance of accuracy versus efficiency. For example, in a scenario where accuracy is paramount, the increased generation length of CoT might be acceptable. Conversely, if computational cost is a major concern, Soft Thinking might be preferred despite the lower accuracy.