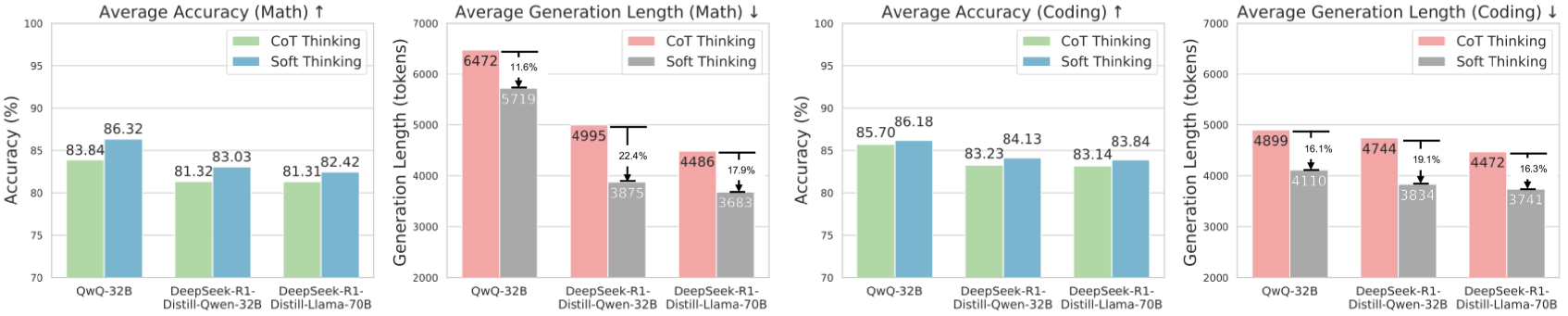
\n
## Comparative Performance Charts of AI Models on Math and Coding Tasks
### Overview
The image displays four bar charts arranged in a 2x2 grid. They compare the performance of three large language models (LLMs) on mathematical and coding tasks. The comparison is made across two key metrics: **Average Accuracy** (higher is better) and **Average Generation Length** (lower is better). For each metric and task, two reasoning methods are contrasted: **CoT (Chain-of-Thought) Thinking** and **Soft Thinking**.
### Components/Axes
* **Chart Layout:** Four distinct bar charts in a horizontal row.
* **X-Axis (All Charts):** Lists three model variants:
1. `QwQ-32B`
2. `DeepSeek-R1-Distill-Qwen-32B`
3. `DeepSeek-R1-Distill-Llama-70B`
* **Y-Axis (Charts 1 & 3 - Accuracy):** Labeled `Accuracy (%)`. Scale ranges from 70 to 100.
* **Y-Axis (Charts 2 & 4 - Generation Length):** Labeled `Generation Length (tokens)`. Scale ranges from 2000 to 7000.
* **Legends:**
* **Charts 1 & 3 (Accuracy):** `CoT Thinking` (light green bar), `Soft Thinking` (light blue bar).
* **Charts 2 & 4 (Generation Length):** `CoT Thinking` (light red/pink bar), `Soft Thinking` (grey bar).
* **Chart Titles:**
1. `Average Accuracy (Math) ↑` (Up arrow indicates higher is better)
2. `Average Generation Length (Math) ↓` (Down arrow indicates lower is better)
3. `Average Accuracy (Coding) ↑`
4. `Average Generation Length (Coding) ↓`
### Detailed Analysis
**Chart 1: Average Accuracy (Math)**
* **Trend:** For all three models, the `Soft Thinking` bar (blue) is taller than the `CoT Thinking` bar (green), indicating higher accuracy.
* **Data Points:**
* `QwQ-32B`: CoT = 83.84%, Soft = 86.32%
* `DeepSeek-R1-Distill-Qwen-32B`: CoT = 81.32%, Soft = 83.03%
* `DeepSeek-R1-Distill-Llama-70B`: CoT = 81.31%, Soft = 82.42%
**Chart 2: Average Generation Length (Math)**
* **Trend:** For all three models, the `Soft Thinking` bar (grey) is shorter than the `CoT Thinking` bar (pink), indicating shorter, more concise outputs. Percentage reductions are annotated.
* **Data Points & Reductions:**
* `QwQ-32B`: CoT = 6472 tokens, Soft = 5719 tokens. **Reduction: 11.6%**.
* `DeepSeek-R1-Distill-Qwen-32B`: CoT = 4995 tokens, Soft = 3875 tokens. **Reduction: 22.4%**.
* `DeepSeek-R1-Distill-Llama-70B`: CoT = 4486 tokens, Soft = 3683 tokens. **Reduction: 17.9%**.
**Chart 3: Average Accuracy (Coding)**
* **Trend:** Similar to math, `Soft Thinking` (blue) yields higher accuracy than `CoT Thinking` (green) for all models.
* **Data Points:**
* `QwQ-32B`: CoT = 85.70%, Soft = 86.18%
* `DeepSeek-R1-Distill-Qwen-32B`: CoT = 83.23%, Soft = 84.13%
* `DeepSeek-R1-Distill-Llama-70B`: CoT = 83.14%, Soft = 83.84%
**Chart 4: Average Generation Length (Coding)**
* **Trend:** Again, `Soft Thinking` (grey) produces shorter outputs than `CoT Thinking` (pink) for all models.
* **Data Points & Reductions:**
* `QwQ-32B`: CoT = 4899 tokens, Soft = 4110 tokens. **Reduction: 16.1%**.
* `DeepSeek-R1-Distill-Qwen-32B`: CoT = 4744 tokens, Soft = 3834 tokens. **Reduction: 19.1%**.
* `DeepSeek-R1-Distill-Llama-70B`: CoT = 4472 tokens, Soft = 3741 tokens. **Reduction: 16.3%**.
### Key Observations
1. **Universal Improvement with Soft Thinking:** Across all three models and both task domains (math and coding), the `Soft Thinking` method consistently results in **higher accuracy** and **shorter generation lengths** compared to `CoT Thinking`.
2. **Magnitude of Gains:** The improvement in accuracy is more pronounced in the math tasks (gains of ~1.5-2.5 percentage points) than in coding tasks (gains of ~0.5-1.0 percentage points).
3. **Efficiency Gains:** The reduction in output length (tokens) is substantial, ranging from 11.6% to 22.4%. The largest relative reduction (22.4%) is seen with the `DeepSeek-R1-Distill-Qwen-32B` model on math tasks.
4. **Model Performance Hierarchy:** The `QwQ-32B` model generally shows the highest raw accuracy scores in both domains under both thinking methods. The two `DeepSeek-R1-Distill` models perform very similarly to each other.
### Interpretation
The data strongly suggests that the **`Soft Thinking` reasoning paradigm is superior to standard `CoT (Chain-of-Thought) Thinking`** for the evaluated models on these benchmarks. It achieves a "best of both worlds" outcome: **improved performance (higher accuracy) with greater efficiency (shorter outputs)**.
This implies that `Soft Thinking` may be a more effective method for eliciting correct reasoning, potentially by reducing verbose or redundant steps in the thought process that `CoT` might generate. The consistent results across different model architectures (Qwen and Llama-based distills) and task types (math and coding) indicate this is a robust finding, not an artifact of a specific model or domain.
The practical implication is significant: deploying models using `Soft Thinking` could lead to more accurate AI assistants that are also cheaper and faster to run due to generating fewer tokens. The charts serve as a clear empirical validation of this method's advantages.