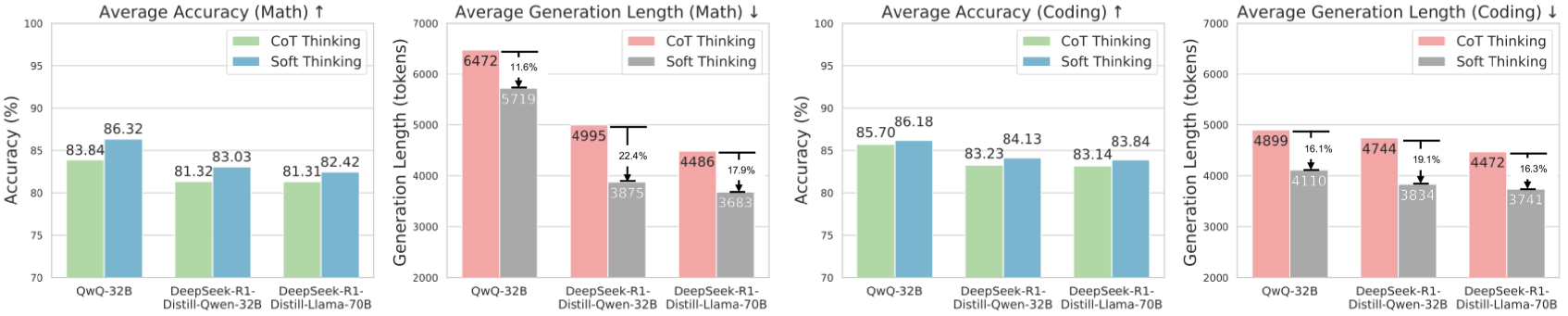
## Bar Charts: Model Performance Comparison (Math & Coding Tasks)
### Overview
The image contains four grouped bar charts comparing three AI models (QwQ-32B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B) across two metrics: **Accuracy** and **Generation Length**, split into **Math** and **Coding** tasks. Each model is evaluated using two reasoning approaches: **CoT Thinking** (Chain-of-Thought) and **Soft Thinking**.
---
### Components/Axes
1. **X-Axes**:
- Models: QwQ-32B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B
2. **Y-Axes**:
- **Accuracy Charts**: Percentage (%) from 70% to 100%
- **Generation Length Charts**: Token count from 2000 to 7000
3. **Legends**:
- **Accuracy Charts**: Green = CoT Thinking, Blue = Soft Thinking
- **Generation Length Charts**: Red = CoT Thinking, Gray = Soft Thinking
4. **Bar Grouping**:
- Each model has two adjacent bars (CoT/Soft) for each metric/task.
---
### Detailed Analysis
#### 1. **Average Accuracy (Math)**
- **QwQ-32B**:
- CoT: 83.84% (green)
- Soft: 86.32% (blue)
- **DeepSeek-R1-Distill-Qwen-32B**:
- CoT: 81.32% (green)
- Soft: 83.03% (blue)
- **DeepSeek-R1-Distill-Llama-70B**:
- CoT: 81.31% (green)
- Soft: 82.42% (blue)
#### 2. **Average Generation Length (Math)**
- **QwQ-32B**:
- CoT: 6472 tokens (red)
- Soft: 5719 tokens (gray, ↓11.6%)
- **DeepSeek-R1-Distill-Qwen-32B**:
- CoT: 4995 tokens (red)
- Soft: 3875 tokens (gray, ↓22.4%)
- **DeepSeek-R1-Distill-Llama-70B**:
- CoT: 4486 tokens (red)
- Soft: 3683 tokens (gray, ↓17.9%)
#### 3. **Average Accuracy (Coding)**
- **QwQ-32B**:
- CoT: 85.70% (green)
- Soft: 86.18% (blue)
- **DeepSeek-R1-Distill-Qwen-32B**:
- CoT: 83.23% (green)
- Soft: 84.13% (blue)
- **DeepSeek-R1-Distill-Llama-70B**:
- CoT: 83.14% (green)
- Soft: 83.84% (blue)
#### 4. **Average Generation Length (Coding)**
- **QwQ-32B**:
- CoT: 4899 tokens (red)
- Soft: 4110 tokens (gray, ↓16.1%)
- **DeepSeek-R1-Distill-Qwen-32B**:
- CoT: 4744 tokens (red)
- Soft: 3834 tokens (gray, ↓19.1%)
- **DeepSeek-R1-Distill-Llama-70B**:
- CoT: 4472 tokens (red)
- Soft: 3741 tokens (gray, ↓16.3%)
---
### Key Observations
1. **Accuracy Trends**:
- **Math**: Soft Thinking consistently outperforms CoT by ~2-3% across all models.
- **Coding**: Soft Thinking slightly edges out CoT, but the gap narrows (≤1% difference).
2. **Generation Length Trends**:
- **Math**: CoT uses significantly more tokens than Soft Thinking (11.6-22.4% reduction).
- **Coding**: Token reduction is smaller (16.1-19.1%) compared to Math.
3. **Model Performance**:
- QwQ-32B shows the largest accuracy gap in Math (83.84% vs. 86.32%).
- DeepSeek-R1-Distill-Llama-70B has the smallest accuracy difference in Coding (83.14% vs. 83.84%).
---
### Interpretation
1. **Efficiency vs. Accuracy Trade-off**:
- Soft Thinking achieves higher accuracy with shorter generation lengths, suggesting it is more computationally efficient.
- CoT Thinking, while less efficient, may provide marginally better performance in structured tasks like Math.
2. **Task-Specific Behavior**:
- Math problems (structured, logical) show larger accuracy improvements with Soft Thinking, possibly due to its ability to bypass verbose reasoning steps.
- Coding tasks (context-dependent) exhibit smaller accuracy gaps, indicating Soft Thinking’s effectiveness in handling nuanced, real-world problems.
3. **Model Scaling**:
- Larger models (Llama-70B) show diminishing returns in accuracy improvements, suggesting architectural limitations in leveraging scale for reasoning tasks.
---
### Spatial Grounding & Validation
- **Legend Placement**: All legends are positioned on the right side of their respective charts.
- **Color Consistency**:
- Accuracy charts: Green (CoT) and Blue (Soft) match bar colors.
- Generation length charts: Red (CoT) and Gray (Soft) align with bar colors.
- **Trend Verification**:
- Math Accuracy: Soft bars are consistently taller than CoT bars.
- Generation Length: CoT bars are taller than Soft bars in both tasks.
---
### Conclusion
The data highlights Soft Thinking as a more efficient and accurate alternative to CoT Thinking, particularly in Math tasks. This suggests potential for optimizing AI reasoning pipelines by prioritizing Soft Thinking where efficiency and accuracy are critical. However, CoT’s slight edge in Coding accuracy may warrant further investigation into hybrid approaches.