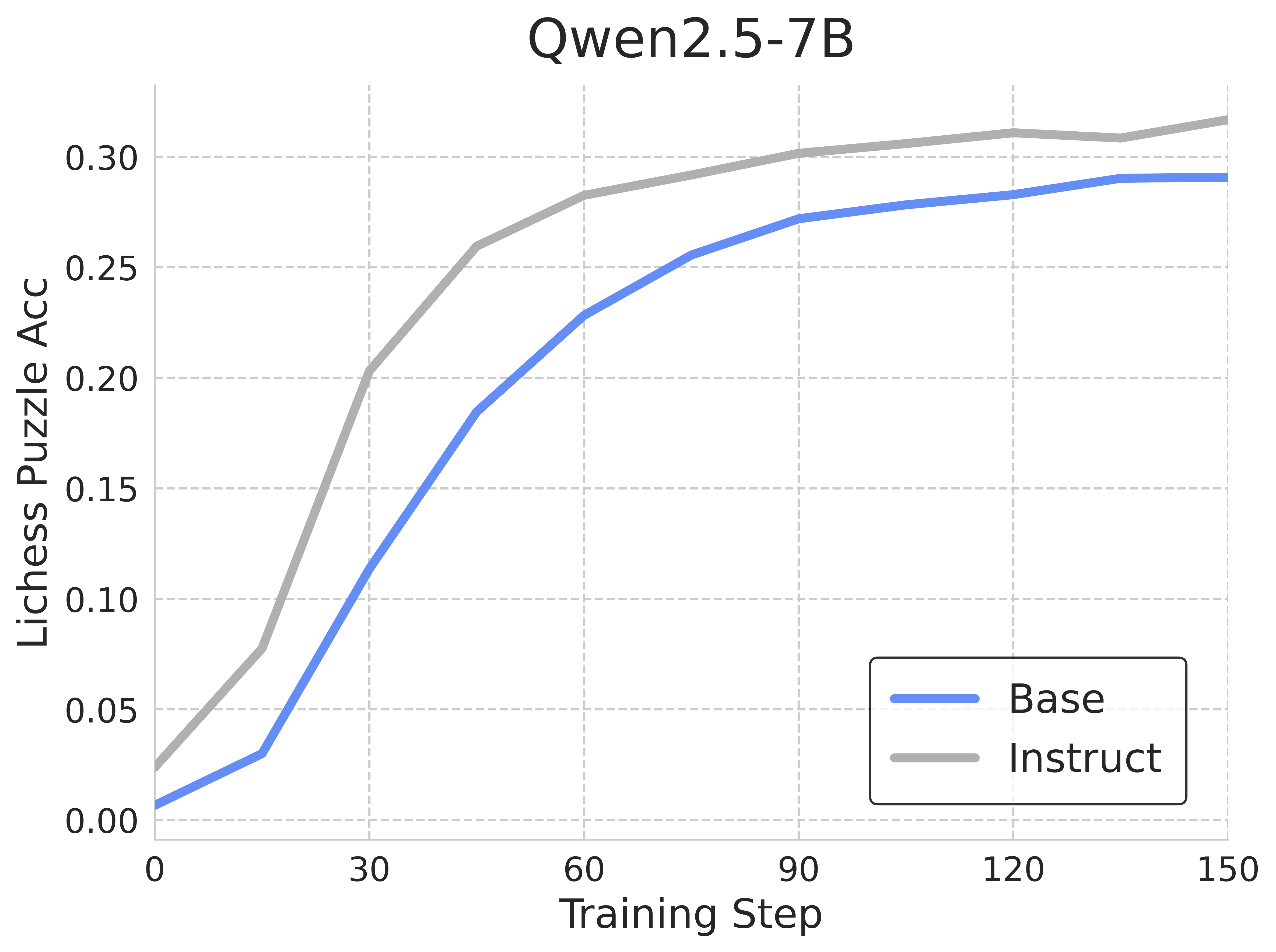
## Line Graph: Qwen2.5-7B Model Performance Over Training Steps
### Overview
The graph compares the Lichess Puzzle Accuracy (Acc) of two models ("Base" and "Instruct") during training. Both models show increasing performance over time, with "Instruct" consistently outperforming "Base" across all training steps.
### Components/Axes
- **Title**: "Qwen2.5-7B"
- **X-axis**: "Training Step" (0 to 150, increments of 30)
- **Y-axis**: "Lichess Puzzle Accuracy (Acc)" (0.00 to 0.30, increments of 0.05)
- **Legend**: Located in the bottom-right corner, with:
- **Blue line**: "Base" model
- **Gray line**: "Instruct" model
### Detailed Analysis
1. **Base Model (Blue Line)**:
- Starts at **0.00** at 0 training steps.
- Gradual increase to **~0.29** at 150 steps.
- Key points:
- 30 steps: **~0.12**
- 60 steps: **~0.23**
- 90 steps: **~0.27**
- 120 steps: **~0.28**
- 150 steps: **~0.29**
2. **Instruct Model (Gray Line)**:
- Starts at **~0.02** at 0 training steps.
- Steeper ascent to **~0.32** at 150 steps.
- Key points:
- 30 steps: **~0.20**
- 60 steps: **~0.28**
- 90 steps: **~0.30**
- 120 steps: **~0.31**
- 150 steps: **~0.32**
### Key Observations
- **Performance Gap**: "Instruct" maintains a **~0.03–0.04 accuracy advantage** over "Base" throughout training.
- **Convergence**: The gap narrows slightly in later stages (e.g., from **0.09** at 30 steps to **0.03** at 150 steps).
- **Plateauing**: Both models show diminishing returns after ~90 steps, with "Instruct" reaching a higher plateau.
### Interpretation
The data suggests that the "Instruct" model's architecture or training methodology inherently enables superior performance in Lichess puzzles compared to the "Base" model. The narrowing gap at later stages implies that while "Base" improves with training, "Instruct" benefits from a more efficient learning process or better initialization. This could reflect differences in:
- **Training data curation** (e.g., "Instruct" may use more targeted examples).
- **Model design** (e.g., "Instruct" might incorporate reinforcement learning or human feedback).
- **Regularization techniques** (e.g., "Instruct" could avoid overfitting more effectively).
The consistent outperformance of "Instruct" highlights the importance of architectural choices in specialized tasks like chess puzzle solving. Further analysis could explore whether this trend holds across other domains or if it is specific to chess-related reasoning.