TECHNICAL ASSET FINGERPRINT
05673d53d6a7fec8673672ac
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
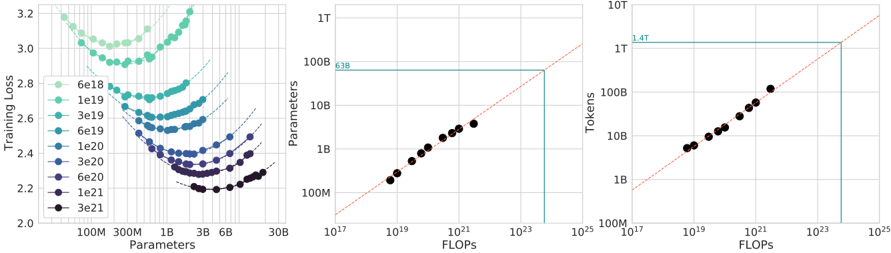
## [Chart Set]: Scaling Laws for Neural Language Models
### Overview
The image contains three horizontally arranged charts that illustrate scaling laws for neural language models, showing the relationship between model size (parameters), training data (tokens), computational cost (FLOPs), and performance (training loss). The charts are presented on logarithmic scales.
### Components/Axes
**Left Chart: Training Loss vs. Parameters**
* **Title:** Training loss vs Parameters (inferred from axes)
* **Y-axis:** "Training loss" (linear scale, range ~2.0 to 3.2)
* **X-axis:** "Parameters" (logarithmic scale, markers at 100M, 300M, 1B, 3B, 6B, 30B)
* **Legend (Top-Left):** A vertical list of colored circles with corresponding compute budgets in FLOPs. From top to bottom (lightest to darkest):
* `6e18` (lightest green)
* `1e19`
* `3e19`
* `6e19`
* `1e20`
* `3e20`
* `6e20`
* `1e21`
* `3e21` (darkest purple/black)
* **Data Series:** Multiple series of colored circles, each forming a U-shaped curve. Dashed lines extend from the minimum point of each curve towards the right.
**Middle Chart: Parameters vs. FLOPs**
* **Title:** Parameters vs FLOPs (inferred from axes)
* **Y-axis:** "Parameters" (logarithmic scale, markers at 100M, 1B, 10B, 100B, 1T)
* **X-axis:** "FLOPs" (logarithmic scale, markers at 10^17, 10^19, 10^21, 10^23, 10^25)
* **Key Elements:**
* A diagonal, red dashed line representing a scaling trend.
* A horizontal, teal solid line intersecting the Y-axis at approximately `63B` (labeled "63B").
* A vertical, teal solid line dropping from the intersection point of the horizontal line and the diagonal trend line down to the X-axis at approximately `10^24` FLOPs.
* Data points: Black circles plotted along the diagonal trend line.
**Right Chart: Tokens vs. FLOPs**
* **Title:** Tokens vs FLOPs (inferred from axes)
* **Y-axis:** "Tokens" (logarithmic scale, markers at 100M, 1B, 10B, 100B, 1T, 10T)
* **X-axis:** "FLOPs" (logarithmic scale, markers at 10^17, 10^19, 10^21, 10^23, 10^25)
* **Key Elements:**
* A diagonal, red dashed line representing a scaling trend.
* A horizontal, teal solid line intersecting the Y-axis at approximately `1.4T` (labeled "1.4T").
* A vertical, teal solid line dropping from the intersection point of the horizontal line and the diagonal trend line down to the X-axis at approximately `10^24` FLOPs.
* Data points: Black circles plotted along the diagonal trend line.
### Detailed Analysis
**Left Chart (Training Loss vs. Parameters):**
* **Trend Verification:** Each colored series (representing a fixed compute budget) forms a distinct U-shaped curve. As the number of parameters increases for a fixed compute budget, the training loss first decreases to a minimum and then increases again. The minimum point of each curve shifts to the right (more parameters) and downward (lower loss) as the compute budget increases.
* **Data Points (Approximate Minima):**
* For compute `6e18` FLOPs: Minimum loss ~2.9 at ~300M parameters.
* For compute `1e20` FLOPs: Minimum loss ~2.5 at ~1B parameters.
* For compute `3e21` FLOPs: Minimum loss ~2.2 at ~6B-10B parameters.
* The dashed lines extending from each minimum suggest the optimal model size for a given compute budget follows a power-law relationship.
**Middle Chart (Parameters vs. FLOPs):**
* **Trend Verification:** The black data points follow a clear, positive linear trend on the log-log plot, indicating a power-law relationship between model parameters and required FLOPs for training.
* **Key Data Point:** The horizontal line at `63B` parameters intersects the diagonal trend line. The corresponding vertical line indicates that training a 63B parameter model requires approximately `10^24` FLOPs.
**Right Chart (Tokens vs. FLOPs):**
* **Trend Verification:** Similar to the middle chart, the black data points follow a positive linear trend on the log-log plot, indicating a power-law relationship between the number of training tokens and required FLOPs.
* **Key Data Point:** The horizontal line at `1.4T` tokens intersects the diagonal trend line. The corresponding vertical line indicates that training on 1.4 trillion tokens requires approximately `10^24` FLOPs.
### Key Observations
1. **Optimal Model Size:** The left chart demonstrates that for any fixed computational budget, there exists an optimal model size (number of parameters) that minimizes training loss. Using more or fewer parameters than this optimum results in worse performance for that budget.
2. **Scaling Laws:** The middle and right charts confirm strong power-law scaling relationships. Both model size (parameters) and data size (tokens) scale predictably with the square root of computational cost (FLOPs) (as indicated by the slope of the diagonal lines on the log-log plots).
3. **Compute Allocation:** The vertical teal lines in the middle and right charts both point to the same FLOPs value (~10^24). This suggests that at this specific compute scale (~10^24 FLOPs), the optimal configuration involves a model with ~63B parameters trained on ~1.4T tokens.
4. **Loss Reduction:** Increasing the compute budget (moving from light green to dark purple curves in the left chart) consistently leads to lower achievable training loss, but requires both larger models and more data.
### Interpretation
These charts collectively visualize the "scaling laws" for neural language models. They provide a framework for predicting model performance and allocating resources efficiently.
* **The left chart is a guide for model sizing.** It answers: "Given my compute budget, how big should my model be?" The U-shaped curves warn against under-parameterization (high loss due to lack of capacity) and over-parameterization (high loss due to insufficient data for the model size, given the fixed budget).
* **The middle and right charts are planning tools.** They answer: "To train a model of size X on Y tokens, how much compute do I need?" The linear trends allow for extrapolation to predict the cost of training larger models or using more data.
* **The intersection at ~10^24 FLOPs** represents a specific, likely state-of-the-art, model configuration. It shows the balanced allocation of resources between model parameters (63B) and data (1.4T tokens) at that scale. The charts imply that deviating from this balance (e.g., using a 100B parameter model with the same compute) would be suboptimal.
* **Underlying Principle:** The data suggests that performance (lower loss) is a predictable function of scale (compute, parameters, data). To improve performance, one must increase all three in a coordinated manner, following the relationships shown. The charts provide the empirical formulas for this coordination.
DECODING INTELLIGENCE...